
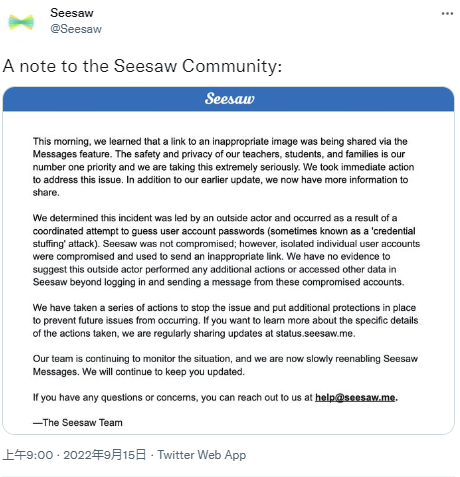
据NBC News报道,一款供家长和教师使用的短信应用的开发商周三表示,其应用遭到黑客攻击,因为一些家长说他们收到了带有一张在互联网上臭名昭著的露骨照片的信息。伊利诺伊州、纽约州、俄克拉荷马州和得克萨斯州的学区负责人周三都表示,这张照片是通过该应用程序Seesaw发给家长和教师的私人聊天记录。
Seesaw的网站显示,有1000万名教师、学生和家庭成员在使用其应用,它拒绝透露有多少用户受到影响。
Seesaw营销副总裁Sunniya Saleem在一份电子邮件声明中说:“特定的用户账户被外部行为者入侵”,“我们正在极其认真地对待此事”。
她说:“我们的团队继续监控这一情况,以确保我们防止这些图片进一步传播,使任何Seesaw用户无法看到。”
该公司在后续的电子邮件中表示,黑客没有获得对Seesaw的管理权限,而是通过所谓的凭证填充攻击攻破了个人用户账户。在这种攻击中,黑客通过以前的数据泄露事件来确定用户名和密码的组合。网络安全专家建议不要在多个网站上重复使用相同的密码,以避免凭证填充攻击。
照片以链接的形式发送给一些家长和老师,bitly是一种流行的链接缩短服务,可以掩盖实际的网络地址。对于一些用户来说,该应用程序在聊天中自动描绘了该图像。
Chris Krampert的孩子在佛罗里达州上小学,他向NBC News提供了一份截屏,显示他妻子的账户向惊恐的父母发送了自动显示在聊天中的图片。该图片是一张臭名昭著的模因照片,其中有一名男子正在进行露骨的行为。
一些学区发布公告,警告家长不要打开通过Seesaw发送的链接。伊利诺伊州汉诺威公园基尼维尔小学20区网站的访问者收到了弹出式警告。它说:“请不要打开今天早上在Seesaw消息中发给你的任何‘bitly’链接。它可能显示为从另一个学校家庭发给你的信息,但请立即删除该信息,不要打开,因为发送了不适当的内容。”
位于纽约哈德逊河畔卡斯尔顿的卡斯尔顿小学在其网站上宣布,它也看到了安全漏洞的证据。它说:“与此同时,如果你需要与你的学生的老师交谈,请向他们发送电子邮件。”
(举报)