
摘要:从盲目试错到数据驱动——一个开发者的模型选型心路历程
一、我的踩坑经历:那个让我成本飙升的"性价比"模型
上个月,我接了一个构建智能代码评审工具的项目。客户要求不高:能分析中等规模的代码库(约 2 万行代码),给出基础的质量建议和潜在漏洞提示。
像大多数开发者一样,我首先想到了成本。"先用个便宜的模型试试",我这样告诉自己。于是选择了一个市场上宣传"极致性价比"的模型,价格确实诱人:每百万token只需几美元。
结果却令人沮丧:模型在处理长代码文件时频繁丢失上下文,生成的评审建议泛泛而谈,甚至出现明显的技术错误。最终,我不得不将任务拆分成数十个小片段处理,重试率高达30%。算上失败请求的成本和额外开发时间,实际成本比直接使用高质量模型高出 3 倍以上。
这次经历让我明白:表面的低价可能是最昂贵的选择。
二、发现新大陆:AIbase如何解决我的信息焦虑
在经历了几次类似的试错后,我开始系统性寻找解决方案。最终发现了AIbase模型选型对比平台(model.aibase.cn/compare),这个工具彻底改变了我选择模型的方式。
在此之前,我的工作流程是这样的:
打开十几个浏览器标签页
在不同模型的官方文档间来回切换
手动制作对比表格
在社区寻找可能过期的评测数据
最终凭直觉做出选择
AIbase一站式解决了这个问题:统一的对比界面、实时更新的价格数据、多维度的能力评分,让我终于能够基于事实而非猜测做出决策。
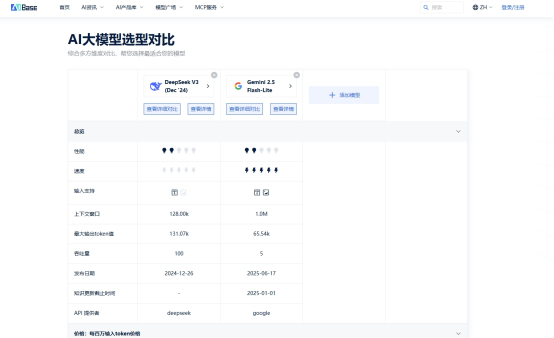
三、实战演示:手把手对比Gemini 2.5 Flash-Lite和DeepSeek-V3
最近的新项目需要在Gemini 2.5 Flash-Lite和DeepSeek-V3 之间做出选择。这是一个需要长上下文支持的代码生成项目,让我带您一步步看我是如何决策的。
第一步:快速添加对比模型
打开AIbase平台,在搜索框中输入"Gemini 2.5 Flash-Lite",点击添加到对比栏。同样操作添加"DeepSeek-V3"。整个过程不到 10 秒钟,无需在多个标签页间切换。
第二步:核心参数一目了然
平台以清晰的表格形式展示关键数据,我最关注的两个维度是:
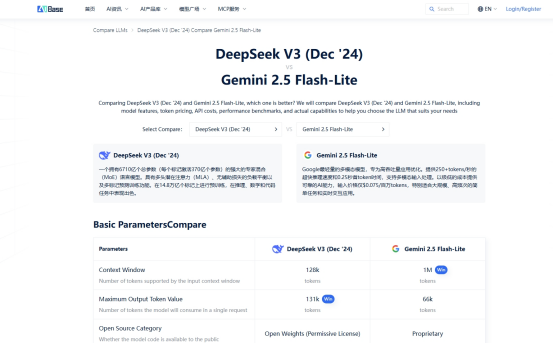
价格对比:
Gemini 2.5 Flash-Lite:输入$0.175/1M tokens,输出$0.70/1M tokens
DeepSeek-V3:输入$0.14/1M tokens,输出$0.56/1M tokens
上下文长度:
两个模型都支持128K上下文,完美满足代码库分析的需求。
仅这一步,就为我节省了以往需要花费半小时查阅文档的时间。
第三步:深度分析能力特长
通过平台提供的多维能力评分,我发现了关键差异:
代码能力:
DeepSeek-V3 在代码生成和理解方面得分显著更高
Gemini 2.5 Flash-Lite在通用任务上表现均衡,但代码专项能力稍逊
推理能力:
两个模型在逻辑推理方面得分相近,都能很好地理解代码逻辑
长上下文处理:
平台数据显示,DeepSeek-V3 在长上下文任务中的表现更加稳定
基于这些数据,结合我的代码生成项目需求,DeepSeek-V3 成为了更合适的选择。
四、价值升华:数据驱动如何为我节省时间和金钱
这次选型过程只花费了我不到 15 分钟,但却带来了显著的价值:
时间节省:相比之前数小时的研究,现在可以在咖啡还没凉的时候完成决策
成本优化:选择最适合的模型,避免了隐性成本和重试开销
信心提升:基于数据而非猜测做决策,项目规划更加精准
最重要的是,我学会了没有"最好"的模型,只有"最适合"的模型这个核心原则。不同的项目需求对应着不同的最优解,关键是要有可靠的数据来支撑这个判断。
五、给开发者的建议
经过这次经历,我想分享给所有面临模型选择困境的开发者:
不要被表面价格迷惑:计算总拥有成本,包括失败重试、额外开发和处理时间
明确你的优先级:是追求极致性价比,还是需要特定能力优势?
善用专业工具:AIbase这样的对比平台能帮你节省大量研究时间
小规模试错:最终决策前,用真实数据做小规模测试验证
模型选型不应该是一场赌博,而应该是一个基于数据的理性决策过程。希望我的经验能帮助你避开那些我曾经踩过的坑,让AI模型真正成为你项目的助力而非负担。
如果你也在为模型选择而苦恼,不妨尝试一下数据驱动的方法——或许你会发现,最适合你项目的那个模型,一直都在那里等着被你发现。
(举报)