
一、真实困境:模型成本为何成了“糊涂账”?
某AI创业团队负责人曾吐槽:
*“调用GPT-4做智能客服,光研究定价文档就花半天——输入/输出token分开计费、不同上下文长度价格差3倍、图片识别另算费用...最后开发完才发现月成本超预算40%”*
这类问题背后是行业痛点:
参数复杂:Token计算、上下文分级、微调附加费、多模态叠加计费
价格波动:主流模型厂商平均每季度调整1次定价(如Anthropic近期刚下调Claude3成本)
对比低效:手动制表对比GPT-4/Claude/Gemini等模型,需收集10+份定价文档
二、破局方案:AIbase计算器如何三步解决
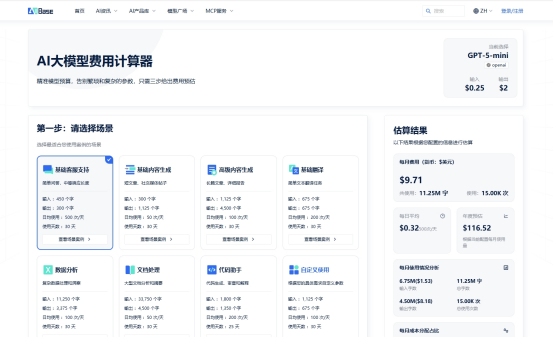
▶ 第一步:选择场景 → 自动匹配参数
无需手动查文档!针对常见场景预设关键参数
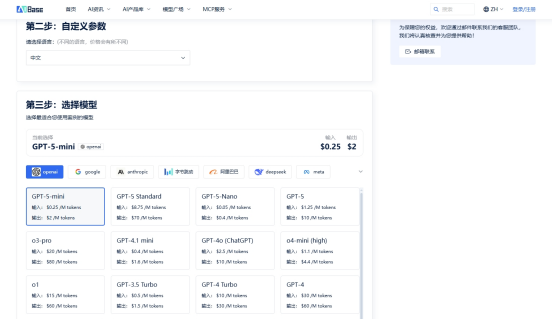
▶ 第二步:输入用量 → 实时联动报价
在计算器页面输入月均用量,即时生成对比
动态追踪机制:当Anthropic在8月12日下调Claude3价格时,数据库72小时内完成同步
▶ 第三步:获取明细 → 规避隐藏成本
深度拆解费用构成,暴露易忽略项:
✅ 标注附加费
✅ 提示区域性差价
三、真实用户场景验证
案例1:跨境电商客服系统选型
需求:日均处理5000次英文咨询
传统做法:
团队用3天制作对比表,因忽略GPT-4的“128K上下文溢价”,导致实际成本超估35%
使用计算器后:
选择“对话”场景 → 自动载入8K上下文参数
输入150万token/月 → 弹出成本排序:
现Command R+的“请求次数附加费”提示 → 追加10%缓冲预算
案例2:高校实验室模型测试
需求:对比7个开源模型微调成本
计算器操作:
勾选“微调实验”模式 → 显示GPU小时费矩阵
输入Llama3-70B/100小时 → 显示:
▸ 基础运算费
▸ 存储附加费
▸ 总成本区间(按实验周期浮动)
导出对比报告直接申请经费
四、为什么开发者信赖这个工具?
数据溯源保障
每项价格标注来源(如OpenAI官网/Anthropic公告页截图)
变更记录可查(Gemini1.5Pro在7月降价18%的历史数据)
动态防御超支
设置“用量浮动预警”(超预设值20%时触发提醒)
生成带缓冲系数的预算方案(推荐+15%容错空间)
覆盖决策全场景

五、立即体验精准成本掌控
与其在定价文档和试错中消耗精力,不如用工具建立确定性:
访问AIbase大模型计算器
→https://model.aibase.com/zh/calculator
适合人群:
需要控制API调用成本的CTO/技术经理
申请科研经费的实验室团队
评估模型商业化可行性的产品经理
“以前做预算像开盲盒,现在用计算器就像有了成本导航仪”
——某AIGC初创公司技术总监2024年8月反馈
核心价值总结:
告别手动收集碎片化定价文档
规避参数理解偏差导致的预算陷阱
用动态数据支撑技术决策
技术决策的本质是权衡性能与成本,而精准的成本预算是理性决策的第一步。
(举报)