
快科技3月11日消息,国产大模型DeepSeek-R1爆火后,许多第三方平台陆续接入了该模型,比如腾讯、阶跃星辰、蚂蚁集团、百度、字节跳动等等。
今日,中文大模型测评基准SuperCLUE发布DeepSeek-R1联网搜索能力首测,公布了10家第三方平台测评结果。
从结果来看,腾讯元宝是本次测评中唯一一个超过80分的第三方平台,以80.61分领跑联网搜索测评榜单,腾讯元宝在总分、基础检索能力和分析推理能力三个关键指标上均位列第一。
阶跃AI以74.49分的总分位居第二,支付宝百宝箱以73.47分位居第三,而其他平台在本次测评中则处于不同的梯队,性能存在一定的差异。
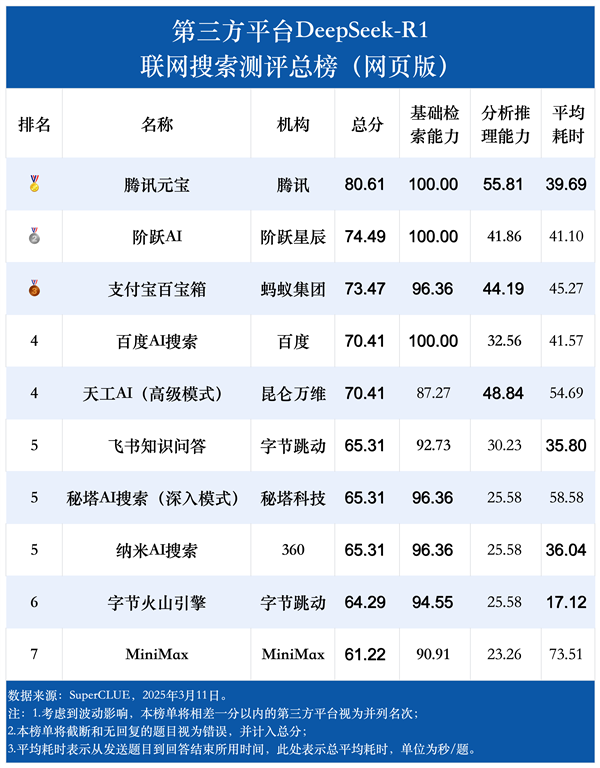
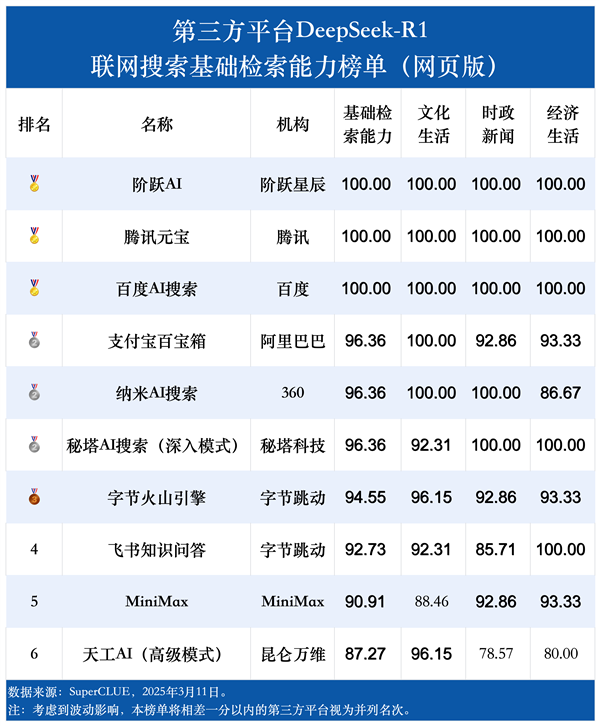
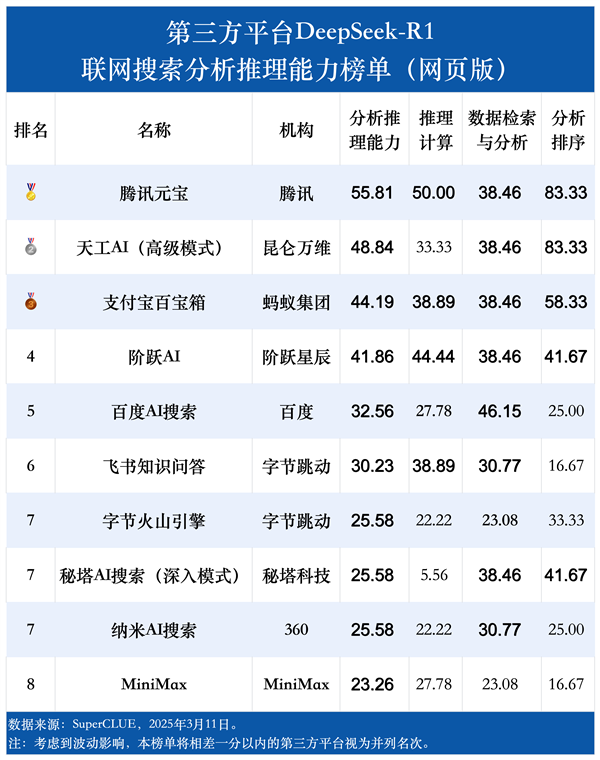
各个第三方平台在基础检索能力上平均得分为95.45,而在分析推理能力上的平均得分仅有35.35,相差近60分。
同一平台在基础检索能力和分析推理能力两大维度上的表现也同样差异明显,所有平台的分析推理能力得分都明显低于基础检索能力。
SuperCLUE表示,这反映出在更高级的认知任务,例如理解、分析、推理和解决复杂问题方面,仍有很大的进步空间。
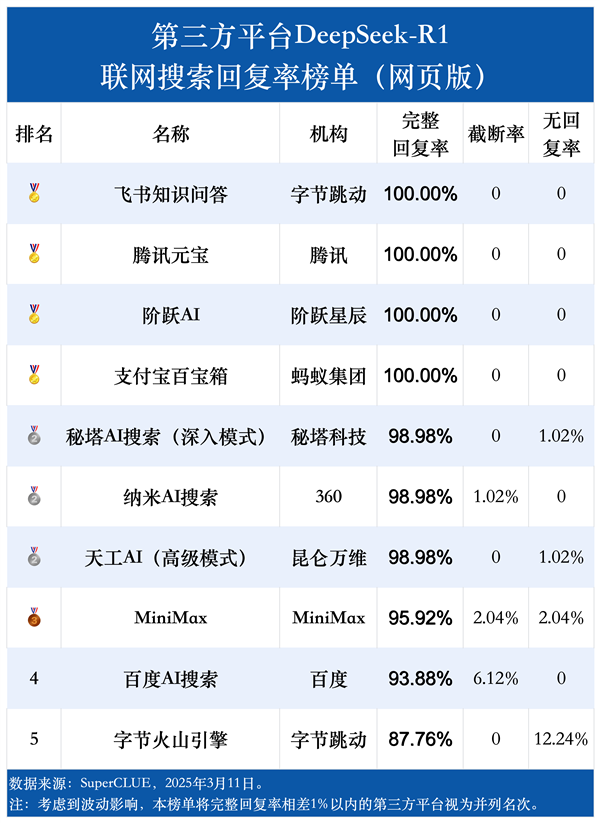
回复率上,飞书知识问答、阶跃AI、腾讯元宝和支付宝百宝箱在联网搜索回复率方面表现优秀,完整回复率均为 100%,截断率和无回复率均为零,成为第一梯队。
秘塔AI搜索、纳米AI搜索和天工AI紧随其后,构成第二梯队,其他平台也均有超过85%的完整回复率,都表现出了较强的稳定性。
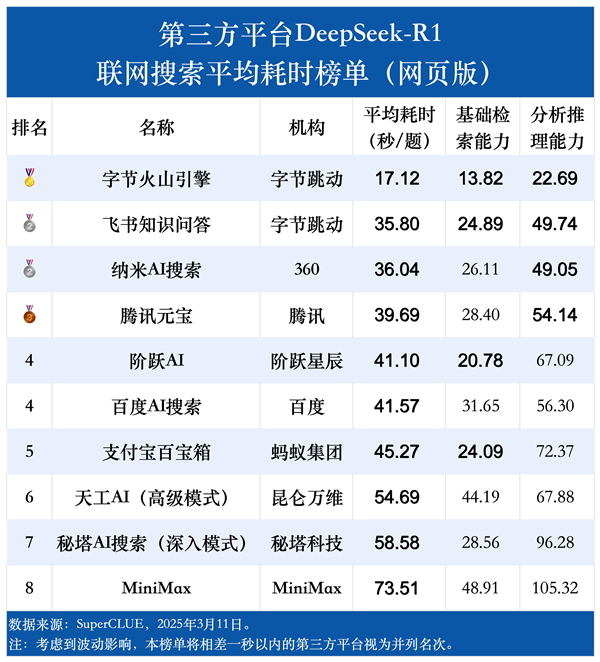
耗时方面,总平均耗时从最少的字节火山引擎(17.12秒/题)到最多的MiniMax(73.51秒/题),差距非常显著。
整体来看,耗时分布范围较广,不同平台之间的搜索效率差异较大。
另外,所有平台在分析推理能力上平均耗时都明显高于基础检索能力。
(举报)