
近日,中国人工智能公司 DeepSeek 发布 DeepSeek-R1 大模型,在性能上与 OpenAI 的 o1 模型不相上下,且完全开源。
更引人注目的是,DeepSeek 成本极低,其基础模型训练仅耗资 560 万美元,而美国公司在人工智能技术上的投入往往动辄数亿甚至数十亿美元。
DeepSeek 无需大量的计算卡进行训练,颠覆了人工智能行业,对以 ChatGPT 为首的人工智能模型产生了巨大冲击。

DeepSeek 的出现对凭借 AI 显卡爆火的英伟达造成严重打击,引发了市场对 AI 算力市场泡沫的质疑,芯片股纷纷暴跌。
其中,英伟达跌幅高达 17%,单日市值蒸发 5950 亿美元,接近 6000 亿美元,创下美股单日最大跌幅记录。
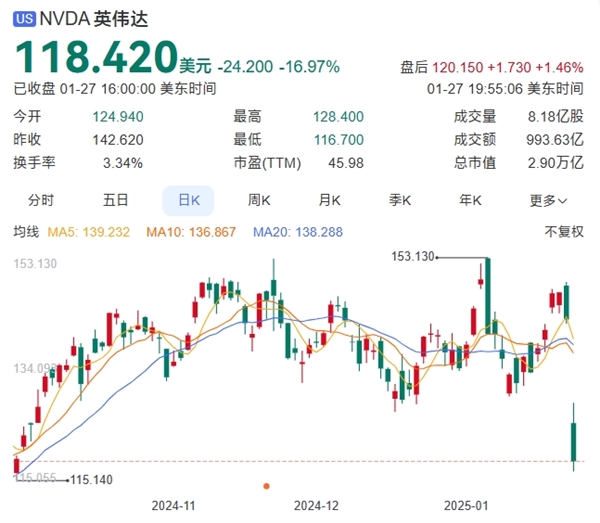
英伟达表示,DeepSeek 的 R1 模型是人工智能领域的一大进步,但强调运行 AI 模型仍需要大量的高性能英伟达 GPU 和网络。
除了英伟达,其他美股科技巨头也遭遇大幅下跌,包括谷歌-C(跌 4.03%)、超微半导体(跌 6.37%)、博通(跌 17.40%)和阿斯麦(跌 5.75%)。
(举报)