
印度汽车巨头Ola进军AI芯片市场
据悉,印度汽车制造商Ola已宣布将于2026年推出国内首款自主研发的AI芯片,采用ARM架构。
Ola公司的创始人Bhavish Aggarwal被誉为印度的"马斯克",他以其直言不讳的个性和对本地制造业的积极支持,与埃隆·马斯克有着相似的特质。
Aggarwal认为,探索AI领域对印度至关重要,而不是依赖第三方解决方案。
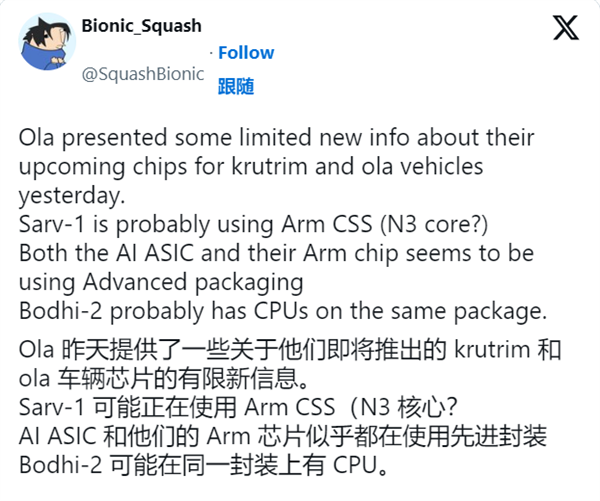
首批三款芯片将于2026年推出
Ola Electric计划从2026年开始推出首批三款AI芯片:Bodhi 1、Ojas和Sarv 1。

- Bodhi 1:印度首款自主研发的AI芯片,专为AI推理任务设计,适用于大型语言模型和高性能视觉处理应用。
- Ojas:旨在满足边缘AI解决方案的增长需求,适用于汽车、移动和物联网等多个领域。
- Sarv 1:一款基于ARM指令集的通用服务器CPU,针对数据中心行业的AI计算需求而设计。
Ola Electric计划与全球一流代工厂合作进行芯片生产,可能是台积电或三星。
(举报)
- 相关推荐
-
零跑汽车:2026年冲击100万辆销量!
零跑汽车今日官宣,截至目前,2025年度累计销量已超50万台,提前完成今年年度目标。 随后,零跑汽车创始人朱江明在朋友圈发文称,2026年将冲击100万辆销量! 从年销不足10万辆到提前达成50万辆目标,零跑的增长速度远超行业预期。 这背后是其全域自研 精准定价”策略的落地:C系列、T系列车型覆盖10-20万元主流
-
小鹏将推出3款全球化Robotaxi 2026年同步开启试运营
小鹏汽车在2025科技日宣布,将于2026年推出三款全栈自研L4级Robotaxi,同步开启试运营。该车型搭载4颗图灵AI芯片,算力达3000TOPS,配备第二代VLA模型,具备强大泛化学习能力,能自适应全球不同交通习惯。作为中国首款全栈自研Robotaxi,无需额外改装,不依赖高精地图即可实现量产。车辆提供两套智驾方案,分别侧重通勤效率与极致安全,并在六大关键系统采用双冗余设计,确保行驶安全。小鹏还将开放Robotaxi SDK,与高德地图等伙伴共建全球服务生态。
-
端侧AI驱动产业链变革,elexcon2026聚焦芯片/存储/嵌入式核心器件创新
近期华为、三星、追觅、阿里巴巴等科技企业密集发布智能穿戴新品,推动设备从“手机配件”向“独立智能终端”转型。这一趋势正深刻影响上游技术路径与产业格局,在AI芯片、存储与嵌入式领域引发新一轮技术升级与价值重构。中国成为全球创新引擎,2025年第二季度全球腕戴设备出货量同比增长12.3%,中国市场增速达33.8%,占据全球近半份额。端侧AI驱动技术升级,供应�
-
曝折叠屏iPhone配2400万屏下摄像头 预计2026年秋亮相
近日,摩根士丹利发布重要信息,揭示了苹果公司即将推出的首款折叠屏iPhone的摄像头配置细节。据透露,这款具有里程碑意义的旗舰手机将首次采用屏下摄像头技术,配备一颗高达2400万像素的屏下摄像头,这在苹果历史上尚属首次。
-
全球首款2nm手机芯片来了!三星Galaxy S26首发 明年2月见
快科技11月3日消息,据媒体报道,三星将于2月25日在旧金山举行Galaxy Unpacked活动,正式推出年度旗舰Galaxy S26系列。据悉,Galaxy S26系列一共推出3款机型,包括Galaxy S26、Galaxy S26Plus和Galaxy S26Ultra,该系列全球首发Exynos2600,这是行业内第一款2nm手机芯片。规格方面,Exynos2600采用三星2nm工艺制程,采用10核心设计,CPU包括1个3.80GHz超大核、3个3.26GHz核心以及6个2.76GHz核心,其单核成绩�
-
特斯拉Cybercab不配备方向盘和踏板 预计2026年二季度下线
特斯拉CEO马斯克透露,Cybercab无人驾驶出租车将于2026年第二季度量产。该车型颠覆传统设计,无方向盘和踏板,完全依赖FSD全自动驾驶技术,采用纯视觉方案。整车成本预计低于3万美元,配备超大后备箱和鸥翼门,内饰极简仅设中控屏。车辆支持感应充电,专为无人出租场景优化,将推动汽车行业变革。
-
新生儿喝什么品牌的奶粉更好?关注2026奶粉趋势报告get佳贝艾特悦白
新手妈妈分享选择佳贝艾特悦白羊奶粉的经历:因母乳不足转为混合喂养,经宝妈群推荐关注吸收和低敏性。该奶粉含OPL结构脂提升吸收率,减少宝宝胀气;通过降低过敏蛋白含量及北大医学部实证,敏感率下降42%。作为全球羊奶第一品牌,经1493项检测全部合格,从奶源到成品全程可控。建议新手父母关注吸收、低敏、安全三大核心,选择适合宝宝的产品。
-
三星Galaxy Z Fold7以创新AI体验实现全场景“一步智联”
三星Galaxy Z Fold7通过Galaxy AI与多模态技术深度融合,重新定义智能手机价值。其极致轻薄折叠设计结合8英寸沉浸屏,搭载升级版Bixby实现语音、文本、视觉的智能交互,支持多任务并行处理。"即圈即搜"简化信息获取,AI助手能转录音频、生成摘要、规划行程,并具备专业影像编辑能力。从办公到生活场景,该设备以直观操作提升效率,成为用户可靠的智慧伴侣。
-
字节旗下AI编程工具TRAE SOLO发布 面向所有用户开放
字节跳动AI编程工具TRAE SOLO正式版发布,面向国际用户开放。该工具提供IDE和SOLO两种开发模式:IDE模式在保留原有流程基础上增强智能问答、代码补全等AI能力;SOLO模式以AI为主导,能理解开发目标、调度工具并独立完成从需求分析到代码实现的全流程。这标志着AI编程从工具增强迈入流程重构新阶段,实现覆盖软件开发全流程的高度自动化。
-
得一微荣获2025中国汽车新供应链百强,国产存力芯片支撑汽车智能升级
2025年10月30日,第七届“金辑奖”在上海举行。得一微电子凭借车规级存储芯片的自主创新和规模化量产,入选“中国汽车新供应链百强”,彰显国产高可靠存储芯片在支撑汽车智能化进程中的核心价值。本届奖项聚焦ADAS、智能座舱、汽车软件与人工智能等十大细分领域,旨在推动中国汽车产业技术升级。得一微围绕存储控制、存算互联等核心技术构建智能处理范式,其车规级存储产品已广泛应用于主流车企并实现规模化量产,将持续以安全可靠的国产存储解决方案助力汽车智能化发展。