
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
新鲜AI产品点击了解:https://top.aibase.com/
1、百度AI原生应用“橙篇”APP上线 集成智能搜索、AI热点推荐等功能
百度文库推出全新AI原生APP“橙篇”,集成了智能搜索、AI热点推荐等功能,引入了多图快速合成视频、超长篇幅文章创作和智能文件内容摘要技术。用户可通过文字或语音与应用交流,支持一键生成长文。

【AiBase提要:】
🔍 先进智能搜索和AI热点推荐功能
📝 多图快速合成视频、超长篇幅文章创作、智能文件内容摘要技术
💬 强大的对话交互能力,一键生成长文
2、英伟达开源新突破:新模型训练算力节省1.8倍!
英伟达开源了两款新型大模型,通过结构化剪枝和知识蒸馏训练方法,显著降低了数据和算力需求,节省了1.8倍算力成本。这一举措将AI领域推向更高效的方向,展示了英伟达在AI技术上的领导地位。
【AiBase提要:】
🚀 英伟达开源新型大模型,通过剪枝和蒸馏方法降低训练成本。
💡 结构化剪枝简化模型结构,保留权重矩阵结构,适合在GPU、TPU等硬件高效运行。
🎓 知识蒸馏提升性能,学生模型通过模仿教师模型深层理解,保持出色性能。
详情链接:https://huggingface.co/nvidia/Nemotron-4-Minitron-4B-Base
3、Midjourney网页版更新:推全新图像编辑器,应对FLUX.1挑战
Midjourney推出全新网络编辑器,整合多项图像操作,满足用户需求。更新体现紧迫感,面对FLUX.1挑战。功能创新是重要尝试,以提高用户体验和吸引用户。竞争激烈,Midjourney需保持图像质量优势,持续推出新功能保持领先地位。
【AiBase提要:】
✨ 整合多项图像操作,提高操作效率,交互逻辑清晰明了。
🔥 面对FLUX.1挑战,更新体现紧迫感,压力增加。
💡 功能创新是重要尝试,全面升级编辑器以优化用户体验。
详情链接:https://top.aibase.com/tool/midjourney
4、阿里巴巴公布2025财年Q1财报:通义大模型下载量破2000万
阿里巴巴集团公布了2025财年第一季度的业绩报告,阿里云业绩突出,营收同比增长6%,AI产品收入实现三位数增长,公共云业务增长稳健。阿里云将继续投资客户和技术领域,特别是在AI技术和基础设施方面,以保持市场领先地位。

【AiBase提要:】
🚀 阿里云营收同比增长6%,达到265.49亿元。
💡 AI产品收入实现三位数增长,经调整EBITA利润同比增长155%。
💻 阿里云全面支撑巴黎奥运会,成为独家云服务商,提供云计算及AI服务,推动赛事转播质量提升。
5、收到28页侵权告知函!秘塔AI搜索不再收录知网文献题录及摘要数据
秘塔AI搜索团队收到知网的侵权告知函,决定不再收录知网文献题录及摘要数据。团队强调知识的流动价值,表示尊重知网的选择,并将与其他知识库合作。秘塔科技致力于智能化知识发现,提供快速精准的文献查找服务。
【AiBase提要:】
💡 秘塔AI搜索收到知网侵权告知函,停止收录知网文献题录及摘要数据。
💡 知识的流动价值被强调,科学文献开放获取对知识公平获取和科学研究至关重要。
💡 秘塔AI搜索将与其他中英文权威知识库合作,推动知识的发现与传播。
6、谷歌Imagen3发布 细腻图像生成体验获好评
谷歌最新图像生成工具Imagen3在Test Kitchen平台上推出,生成细腻、光影效果更佳的图像。用户体验良好,可通过描述生成详细图像,但存在生成限制。与Grok工具相比,Imagen3过滤功能更完善,避免争议性内容。然而,谷歌早前聊天工具生成图像引发争议。

【AiBase提要:】
🖼️ 新版Imagen3在Test Kitchen平台推出,生成细腻、光影效果更佳的图像
🔍 用户可通过描述生成详细图像,编辑功能简单易用
⚠️ 存在生成限制,无法生成公众人物图像,但可绕过限制创建相似形象
7、清华大学推出超万字生成式AI系统LongWriter,挑战人类作家
清华大学研发的LongWriter AI系统突破性地能生成超过10,000字的连贯文本,为长篇写作带来新可能。AI模型输出长度与训练文本长度相关,研究团队成功提升生成文本长度。技术面临虚假信息、竞争加剧、知识产权挑战,需要合理利用与监管。
【AiBase提要:】
📚 LongWriter AI系统改变长篇写作方式
🚀 AI模型输出长度与训练文本长度相关
⚖️ 技术面临虚假信息、竞争加剧、知识产权挑战
详情链接:https://top.aibase.com/tool/longwriter
8、Pindrop推AI音频伪造检测工具Pulse Inspect
Pindrop推出的AI音频伪造检测工具Pulse Inspect准确率高达99%,为用户提供快速、准确的伪造分数反馈,帮助组织应对音频伪造风险,维护品牌信誉。该工具不局限于特定供应商的检测,覆盖多种生成工具,适用于多种音频和视频文件。Pindrop计划根据市场需求推出更实惠的定价方案,满足不同用户的需求。

【AiBase提要:】
🌟 高准确率: Pulse Inspect能以99%的准确率检测AI生成的音频伪造。
🎤 多功能应用: 适用于多种音频和视频文件,不限于特定生成工具。
📈 实惠定价: Pindrop计划根据市场需求推出更实惠的定价方案,满足不同用户的需要。
详情链接:https://www.pindrop.com/products/pulse-inspect
9、谷歌AI生成的搜索摘要改变引用来源展示方式
谷歌推出的AI生成的搜索摘要在全球六个国家展开,改变了用户获取信息的方式,提高了用户的导航体验。用户可以保存摘要并简化内容,同时新增的链接展示方式让用户更方便找到感兴趣的内容。谷歌在不断完善功能的同时,也面对挑战并采取措施确保质量和安全。

【AiBase提要:】
🌍 AI 生成搜索摘要在六个国家推出,改变了引用来源的展示方式。
🔗 新增的链接展示方式让用户更方便找到感兴趣的内容。
💾 用户可以保存 AI 摘要,便于日后查看,同时增加了简化功能。
10、AI监控画面惊呆网友!马斯克竟在超市当起小偷?Grok+Flux=恶搞无限
文章揭示了网友们利用AI恶搞工具Grok和Flux展开的狂欢活动,虚拟世界中的无限可能性。马斯克被恶搞成超市小偷,引发网友疯狂讨论和围观。尽管AI的创作范围广泛,但也引发了对道德底线和安全意识的担忧。马斯克则认为这是一个乐趣和创意的过渡阶段,展现了对AI发展的大胆态度。

【AiBase提要:】
🤖 AI恶搞工具Grok和Flux带来前所未有的虚拟世界狂欢活动
🤣 网友们创作出荒诞画面,包括马斯克在超市当小偷和川普与马斯克互动等
⚠️ 对AI道德底线和安全意识的担忧,以及马斯克对AI发展的大胆态度
详情链接:https://x.com/skirano/status/1824146538463191540https://x.com/dreamingtulpa/status/1824202643935248734
11、李飞飞AI初创公司World Labs2个月内完成2轮融资 估值超10亿美元
在人工智能领域,由斯坦福大学著名AI教授李飞飞创立的神秘创业公司World Labs引起广泛关注。公司在短短两个月内完成两轮融资,估值超过10亿美元,展现出投资者对其潜力的巨大信心。虽然商业模式尚需验证,但其专注于三维AI技术的快速发展令人期待。
【AiBase提要:】
🚀 知名科学家创业受追捧,李飞飞的声誉吸引大量投资。
🌐 三维数据的重要性日益增长,AI模型需求多样化。
💰 融资速度加快,AI领域投资热度高,商业化挑战仍需时间验证。
12、AI视频聊天对象居然比真人还会聊?TavusAI员工反应速度让你怀疑人生!
Tavus的创业小分队推出了神器级视频聊天AI,Conversational Replicas by Tavus,引发科技圈轩然大波。这款AI不仅反应速度惊人,还能根据表情变化做出反应,简直让人怀疑是真人操作。用户可与虚拟同事卡特互动,体验其幽默风趣,快如闪电的反应速度。Tavus还提供多种AI角色选择和自定义对话背景,技术革新不断,速度与激情并存。
【AiBase提要:】
🚀 反应速度惊人,堪比真人,栩栩如生。
🤖 卡特互动有趣,幽默风趣,解围及时。
💡 提供多种AI角色选择和自定义对话背景,技术革新不断。
详情链接:https://www.tavus.io/careers
13、Geekbench推出新AI基准测试,评估设备处理AI任务的性能
作为最新推出的跨平台工具,Geekbench AI专注于评估设备在AI密集型工作负载下的表现。通过测量CPU、GPU和NPU,它能够判断设备在处理机器学习应用程序时的能力。用户可以在多个平台上下载并测试设备的AI处理能力,了解设备在AI任务上的性能表现。
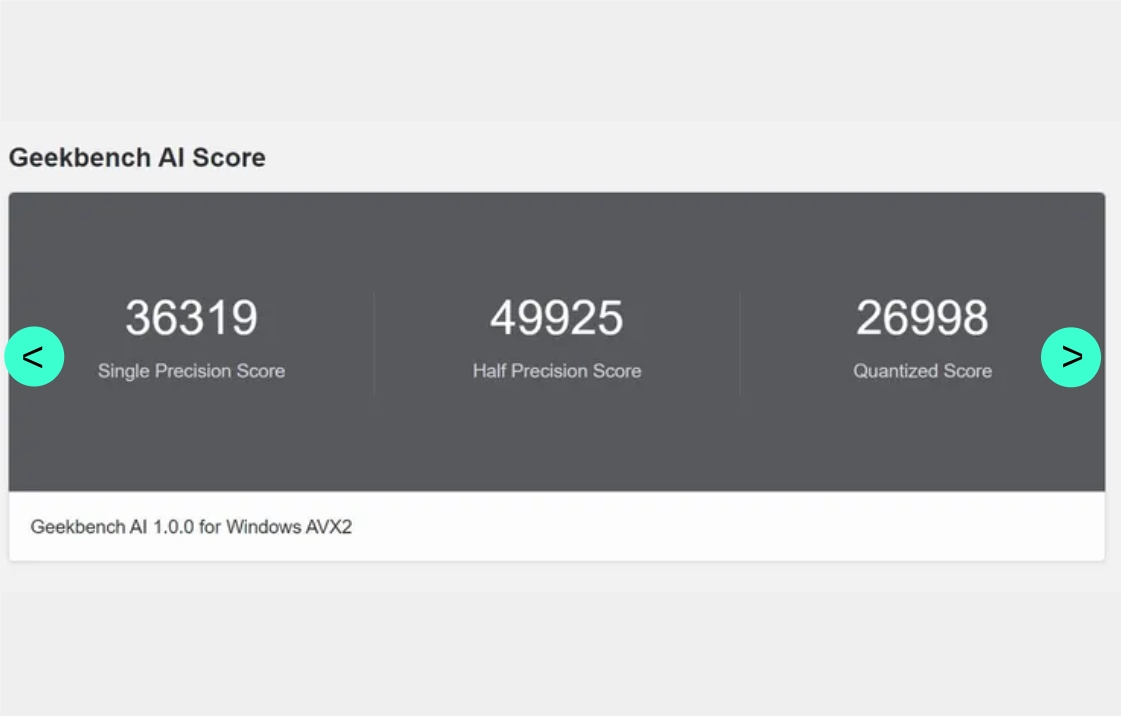
【AiBase提要:】
🖥️ Geekbench AI是一个新的基准测试工具,专注于评估设备在AI任务上的性能。
⚙️ 它通过测量CPU、GPU和NPU,并支持多种机器学习框架,提供准确性和速度的评估。
📱 该工具现已上线,用户可以在多个平台上下载并测试设备的AI处理能力。
(举报)