
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
新鲜AI产品点击了解:https://top.aibase.com/
1、谷歌推超强多模态模型实验版Gemini1.5Pro,排名领先GPT-4o、Claude-3.5Sonnet
谷歌今天推出了Gemini1.5Pro实验版本0801,在人工智能领域取得重大突破。Gemini1.5Pro在多任务表现出色,具有多模态能力和广阔上下文窗口,引发了AI发展和社会影响的讨论。
【AiBase提要:】
🚀 谷歌推出Gemini1.5Pro实验版本0801,在排行榜上领先竞争对手。
💪 该模型在多任务中表现出色,具有多模态能力和广阔上下文窗口。
⚖️ 发布引发AI发展和社会影响的讨论,谷歌寻求反馈以完善模型。
详情链接:https://top.aibase.com/tool/gemini-pro
2、AI图像生成迎来新霸主!开源模型FLUX.1横空出世,Midjourney、DALL·E3紧张了?
在人工智能领域,每一天都可能发生颠覆性的变革。FLUX.1作为一匹令人瞩目的黑马,以其强大性能和开源特性引爆了AI圈。创始人Robin Rombach的权威背景和FLUX.1的创新架构使其成为AI图像生成领域的新霸主,为整个AI行业注入新活力。

【AiBase提要:】
🚀 FLUX.1超越闭源模型和开源SD3系列,性能大幅领先
💡 基于Vision Transformer架构,采用流程匹配训练方法,提升模型性能
🌟 FLUX.1展现出在文本嵌入图片等方面的明显优势
详情链接:https://github.com/black-forest-labs/flux
3、Stability AI推新AI模型Stable Fast3D:半秒内生成3D图像 速度提升1200倍
Stability AI最新推出的Stable Fast3D技术实现了从单张图像快速生成3D图像,处理速度比之前快1200倍,具有广泛的实用价值。该技术基于先进的生成式AI模型,为设计、建筑、零售、虚拟现实和游戏开发等多个行业带来革命性变革。

【AiBase提要:】
😃Stable Fast3D技术实现半秒内生成3D图像,速度大幅提升
👍新模型在设计、建筑、零售、虚拟现实和游戏开发等多个行业具有实用价值
👏Stability AI持续引领图像生成技术发展,从2D到4D不断创新
详情链接:https://top.aibase.com/tool/stable-fast-3d
4、AI视频创作平台Hedra融资1000万美元
近日,AI视频创作领域迎来重磅消息,Hedra成功筹集1000万美元种子资金,引发广泛关注。Hedra推出了视频基础模型Character-1,已有超35万用户创作超160万视频,部分走红网络。多家公司推出视频生成模型,大公司积极参与AI驱动的视频创作。
【AiBase提要:】
🔥 Hedra获1000万美元种子资金,推出Character-1模型。
💡 超35万用户使用Character-1创作超160万视频,部分走红网络。
🚀 多家公司推出视频生成模型,大公司积极参与AI驱动的视频创作。
详情链接:https://www.hedra.com/blog/announcement
5、阿里语音合成模型CosyVoice更新 让AI说话更有人味儿
阿里巴巴推出的最新语音合成模型CosyVoice展示了未来人机交互的美好蓝图,逼真度和灵活性令人惊叹。该技术不仅能生成符合特定性别、年龄和个性的声音,还能模拟人类说话时的自然特征,添加情感和风格,使AI表达更加丰富多彩。CosyVoice与SenseVoice构成FunAudioLLM框架,提升语音交互体验,支持多语言识别和情感识别。技术突破预示着人机交互将迎来全新时代,为教育、娱乐、客户服务等领域带来革命性变化。
【AiBase提要:】
🤖 CosyVoice模型展示未来人机交互蓝图,逼真灵活,生成符合性别、年龄、个性声音,模拟自然特征,添加情感风格。
🔊 FunAudioLLM框架提升语音交互体验,SenseVoice支持多语言识别和情感识别,反应速度快,应用前景广泛。
📚 技术突破预示人机交互新时代,CosyVoice和FunAudioLLM为教育、娱乐、客户服务等领域带来革命性变化。
详情链接:https://top.aibase.com/tool/cosyvoice
6、阿里国际站AI生意助手再升级:文本类AI生成能力完全免费
阿里巴巴国际站总裁张阔宣布AI生意助手的全新发布,包括极简发品功能和AI自动接待功能。AI技术的应用显著降低外贸行业门槛,已有3万家中小企业使用,优化后的商品曝光量提高了37%,支付转化率提升了50%。AI生意助手成为商家高效经营和快速接单的得力助手。更新的三大权益提供更灵活的使用方式,文本类AI生成能力免费,不满意的功能可免费二次生成。将持续更新更多功能。
【AiBase提要:】
🚀 AI生意助手极简发品功能缩短商家发布时间至最快60秒。
💬 AI自动接待功能提升海外买家二次回复率约40%。
💡 AI技术应用降低外贸行业门槛,3万家中小企业使用,商品曝光量提高37%,支付转化率提升50%。
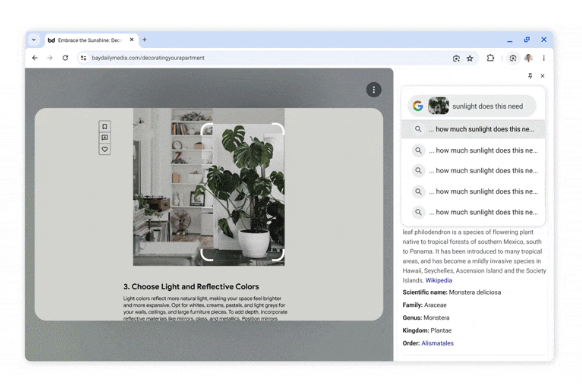
7、桌面ChromeAI搜索升级,引入类似Circle to Search的功能
Google Lens在桌面版Chrome中进行AI驱动的升级,为用户带来更便捷的搜索体验。用户可以通过点击搜索框中的新按钮激活Google Lens,实现多重搜索并查看文本和图像搜索结果。此更新将全球推出,部分功能仅对美国用户开放。另外,Chrome还新增了AI功能,允许用户通过提问搜索历史来查找链接。这些功能将逐步在未来几天或几周内在美国用户中推出。
【AiBase提要:】
🌐 Google Lens在桌面版Chrome进行AI驱动升级,用户可通过点击搜索框按钮激活并进行多重搜索。
📅 更新将在“未来几天”全球推出,部分功能仅对美国用户开放。
💬 Chrome新增可询问搜索历史的AI功能,将“在未来几周内”在美国推出,用户可选择,目前依靠云模型提供结果。
8、以色列人工智能初创公司aiOla推出超高速开源语音识别模型Whisper-Medusa
aiOla推出的Whisper-Medusa语音识别模型在速度上比OpenAI的Whisper提升了50%,并保持了准确性。这一举措将加快语音应用的响应速度,提升效率,降低成本。

【AiBase提要:】
💥 速度提升50%: Whisper-Medusa比OpenAI的Whisper速度快50%
🎯 不损准确性: Whisper-Medusa在提升速度的同时保持了与原模型相同的准确性
📈 应用前景广: Whisper-Medusa有望加快语音应用的响应速度,提升效率,降低成本
9、Suno声称用受版权保护的音乐进行训练模型是“合理使用”
本文报道了美国唱片业协会(RIAA)对音乐生成初创公司 Udio 和 Suno 提起诉讼的情况。Suno 承认使用受版权保护的音乐训练其 AI 模型,并声称这属于合理使用。RIAA 对此表示不认同,认为这是侵权行为。案件结果可能影响相关领域的先例。
【AiBase提要:】
🎶 RIAA 起诉 Udio 和 Suno 使用版权音乐训练模型。
💻 Suno 承认用受版权保护的音乐进行训练模型,但称此为合理使用。
👀 案件结果可能开创影响相关领域的先例。
10、微软首次在SEC文件中将OpenAI列为竞争对手
微软近日在提交给美国证券交易委员会(SEC)的年度10K报告中,首次将其长期合作伙伴OpenAI列为竞争对手,引发业界猜测。这一举动可能受当前反垄断环境影响,微软与OpenAI的关系走向仍有待观察。
【AiBase提要:】
🔍 微软将OpenAI列为竞争对手,引发业界关注。
💰 微软投资OpenAI130亿美元,成为独家云提供商。
🔄 合作伙伴与竞争对手并非互斥,微软与OpenAI关系变化有先例。
11、库克称苹果AI将推动用户升级
苹果公司在2024年第三财季取得了稳健的财务业绩,尤其是服务营收实现了增长。蒂姆·库克透露了关于Apple Intelligence的部分特性和未来发布的新款iPhone16,展望了苹果在人工智能领域的发展。

【AiBase提要:】
📈 苹果公司2024年第三财季总净营收达857.77亿美元,同比增长5%。
📱 iPhone营收达392.96亿美元,Mac和iPad营收增长,服务营收达242.13亿美元。
🚀 Apple Intelligence功能将逐步推出,新款iPhone16即将发布,将支持AI技术。
12、300余名视频游戏演员联合抗议 声讨好莱坞无监管AI使用!
在好莱坞星光闪耀的背后,演员们团结起来抗议无监管AI使用,维护自身权益。这场抗议凸显了人工智能时代下演员生存权的重要性。
【AiBase提要:】
🎭 演员抗议无监管AI使用,维护权益。
💼 人工智能威胁演员生存,声音形象或被滥用。
💰 演员与游戏公司谈判僵局,关键在于谁是表演者。
13、港大与MIT联手打造ItiNera:你的私人AI导游,一键规划完美Citywalk路线!
在都市的喧嚣中,每个人都渴望一场说走就走的citywalk,穿梭于大街小巷,探索历史遗迹,沉浸在当地文化之中。ItiNera系统通过结合空间优化与大型语言模型,提供个性化的城市行程规划服务,为旅行者带来全新的探索城市方式。

【AiBase提要:】
🌆 ItiNera是开放域城市行程规划系统,能根据用户自然语言描述生成个性化行程。
🗺️ ItiNera利用LLM与空间优化模块,提取和排序POIs,打造空间连贯的行程。
🔓 ItiNera已在TuTu在线旅行服务上部署,吸引数千用户使用其城市旅行规划服务。
详情链接:https://arxiv.org/pdf/2402.07204
(举报)