
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
新鲜AI产品点击了解:https://top.aibase.com/
1、阿里巴巴推出AI旗舰应用“新夸克” 全面升级为“AI超级框”
阿里巴巴于3月13日推出了其全新升级的AI旗舰应用——新夸克。这款应用基于阿里通义的先进推理与多模态大模型,整合了多种AI功能,旨在为用户提供无缝的智能体验。新夸克不仅能够进行智能对话,还具备深度思考和执行能力,能够满足用户在多个场景下的需求。
【AiBase提要:】
🤖 新夸克整合了AI对话、深度思考、深度搜索等多种功能,提供一站式服务。
📊 通过智能中枢系统,新夸克能够自动识别用户指令并进行深度执行。
🌐 阿里巴巴计划将通义系列模型的最新成果快速接入新夸克,以增强其功能。
2、谷歌开源新一代多模态模型 Gemma-3:性能卓越、成本降低10倍
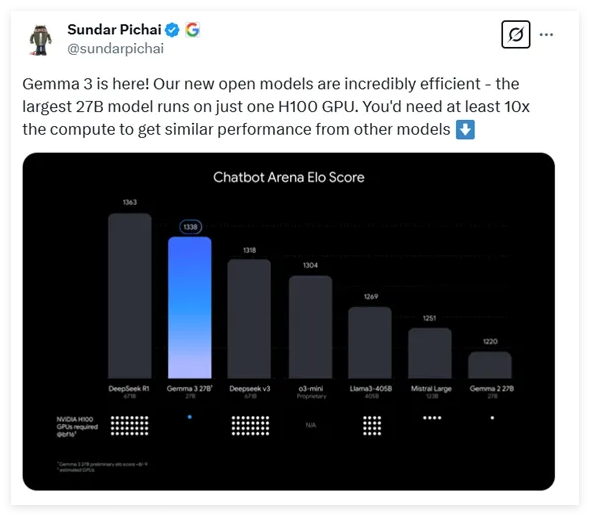
谷歌最新发布的多模态大模型Gemma-3以其低成本和高性能引起了广泛关注。该模型支持多种参数规模,最大可达270亿参数,且仅需一张H100显卡进行高效推理,算力需求显著降低。Gemma-3在对话模型评比中表现优异,支持长文本处理和多模态数据,展现出强大的语言处理能力和创新的架构设计,是当前算力要求最低的高性能模型之一。
【AiBase提要:】
🔍 Gemma-3是谷歌最新开源的多模态大模型,参数范围从10亿到270亿,且算力需求降低10倍。
💡 模型采用创新的架构设计,有效处理长上下文和多模态数据,支持文本与图像的同时处理。
🌐 Gemma-3支持140种语言的处理能力,经过训练优化后在多项任务中表现优异,展现了强大的综合能力。
详情链接:https://huggingface.co/collections/google/gemma-3-release-67c6c6f89c4f76621268bb6d
3、百度文心快码推出Comate Zulu版本 并正式开放公测
百度旗下的文心快码推出了Comate Zulu版本,标志着在智能编程领域的一次重大突破。该版本通过结合文心大模型的强大能力和丰富的编程大数据,为开发者提供了更高效的编程体验。用户可以通过自然语言与系统进行交流,快速搭建项目和理解代码逻辑,大幅提升开发效率。公测活动将持续至3月28日,开发者可以在主流IDE中体验这一创新功能。

【AiBase提要:】
🛠️ 通过全自然语言实现需求,无需编写代码即可自动搭建项目,支持口语交流和图片展示。
📊 快速理解代码库的业务逻辑,提供架构图梳理和智能启发思路,帮助开发者迅速上手新项目。
⚙️ 自动搭建开发环境,支持依赖自动安装和服务自启动,实现从需求到代码的端到端生成。
详情链接:https://comate.baidu.com
4、字节Trae接入硅基流动SiliconCloud 支持DeepSeek多款模型API
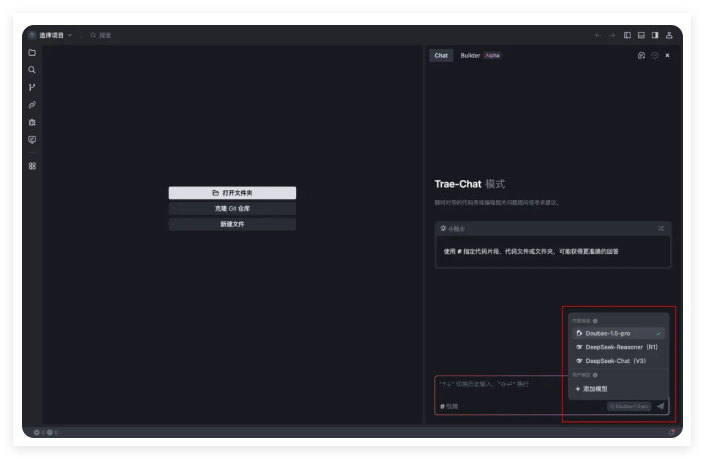
硅基流动平台与字节跳动推出的AI IDE——Trae正式接入,提升了开发者的编程体验。用户可以通过简单的步骤接入多款编码模型,包括DeepSeek-R1、V3等,满足不同需求。平台还提供免费的API服务,助力开发者实现更高效的开发过程。未来,硅基流动将继续扩展模型种类和合作应用,致力于为开发者提供更稳定的服务。
【AiBase提要:】
🔧 Trae接入硅基流动,提供多种高效编码模型,提升编程体验。
🔑 用户可通过简单步骤添加模型,获取API密钥。
🚀 硅基流动致力于提供稳定的API服务,未来将扩展模型种类。
5、王炸更新!谷歌AI Studio再进化:YouTube视频秒懂,AI作画还能保持角色统一
谷歌AI Studio的最新升级引发了科技圈的轰动,用户现在可以直接通过YouTube链接理解视频内容,无需下载和上传。Gemini2.0Flash Experimental模型不仅在视频解析上表现出色,还在图像生成方面展现了惊人的一致性。

【AiBase提要:】
🎥 谷歌AI Studio现在支持直接解析YouTube视频链接,用户可快速理解视频内容。
🖼️ Gemini2.0Flash exp在图像生成方面表现卓越,角色在多张图片中保持一致性。
⚡ 更新标志着谷歌AI Studio从基础模型向应用级工具的转型,影响现有AI工具生态。
详情链接:https://ai.google.dev/gemini-api/docs/vision?lang=python&hl=zh-cn#youtube
6、叫板Sora?潞晨科技开源视频大模型Open-Sora2.0,降本提速
潞晨科技推出的Open-Sora2.0以其仅20万美元的训练成本和110亿参数的强大性能,成功挑战了OpenAI Sora等行业标杆。该模型在多个评测中表现优异,尤其在VBench中与OpenAI Sora的性能差距缩小至0.69%。

【AiBase提要:】
💰 成本低:Open-Sora2.0仅需20万美元训练成本,显著低于行业标准。
📈 性能强:拥有110亿参数,性能接近OpenAI Sora,VBench评测中表现优异。
🌐 开源共享:全流程训练代码开源,推动视频生成技术的共同发展。
详情链接:https://github.com/hpcaitech/Open-Sora
7、阿里通义新视频生成和编辑模型VACE 可控制运动轨迹、替换主体等
阿里通义Wan团队推出了全新的VACE模型,旨在降低视频制作的门槛并提升创作效率。VACE的按条件生成视频功能让用户可以通过文字描述快速实现创意,仿佛拥有了一支梦幻摄制组。此外,VACE还具备多种强大的编辑功能,如物体运动轨迹控制、视频主体替换、风格迁移和视频画面智能扩展等。
【AiBase提要:】
🎬 VACE模型通过文字描述快速生成视频,提升创作效率。
🔄 支持物体运动轨迹控制和视频主体替换,灵活多变。
🖼️ 具备视频画面智能扩展和风格迁移功能,丰富创作表现。
详情链接:https://arxiv.org/pdf/2503.07598
8、理想汽车AI助手理想同学网页版上线:接入DeepSeek R1满血版
理想汽车正式推出其人工智能助手理想同学网页版,标志着其在智能服务领域的进一步扩展。该助手接入了DeepSeek R1V3671B满血版,提供强大的问答能力和跨场景服务协同。用户可以在不同模型之间切换,支持长文本输入及图像问答功能,提升了交互体验。
![]()
【AiBase提要:】
💻 理想同学网页版现已上线,用户可在电脑端使用,拓展智能服务生态。
🔍 接入DeepSeek R1V3671B满血版,支持模型切换和深度思考功能,提升问答能力。
🖼️ 支持千字长文本输入和图像问答,提供更强的用户交互体验。
9、谷歌Gemini2.0Flash放出原生多模态图像生成功能:支持多轮对话式实时编辑
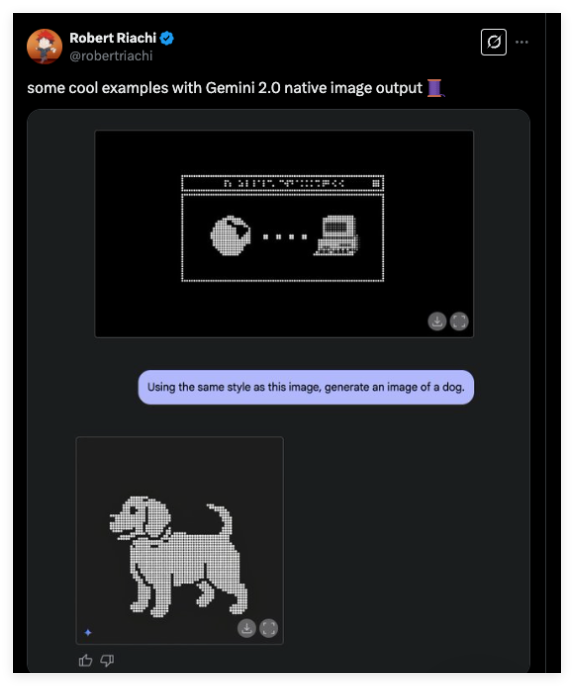
谷歌最新推出的Gemini2.0Flash在AI图像生成领域引入了原生图像生成技术,显著提升了生成效率和准确性。与以往依赖于大型语言模型的方式不同,Gemini2.0Flash实现了图像生成与文本理解的直接集成,使得创作过程更加流畅。
【AiBase提要:】
🎨 原生图像生成:Gemini2.0Flash将图像生成功能直接集成,避免了信息失真,提高了生成效率和准确性。
🖌️ 实时编辑:支持多轮对话式编辑,用户可以用自然语言提出修改意见,AI能够即时响应并调整图像。
📈 企业应用:为营销团队和开发者提供强大工具,快速生成内容,降低设计成本,提高工作效率。
10、Remade AI 开源8款 Wan2.1特效 LoRA,掀起 AI 视频创作新热潮
Remade AI 在 Hugging Face 平台推出了8款基于 Wan2.1模型的开源特效 LoRA,吸引了科技界的广泛关注。这些特效模块不仅能够将静态图像转化为动态视频,还为 AI 视频生成带来了新的创意可能性。

【AiBase提要:】
🎨8款新特效 LoRA 包括挤压、蛋糕化、膨胀等,丰富了 AI 视频创作的可能性。
💻 Wan2.1模型以其高效性和多功能性,成为视频生成领域的顶尖选择。
🌍 Remade AI 邀请全球用户提出定制需求,承诺持续开源更多特效模块。
11、AI对口型革命性突破:Captions新模型Mirage打造超真实UGC视频
Captions公司推出的全新AI模型Mirage,标志着视频生成技术的重大突破。该模型能够实时生成UGC风格视频,面部表情与肢体语言的真实度超越以往技术,简化了视频制作流程,尤其对广告和内容创作者而言,将成本和时间大幅缩减。

【AiBase提要:】
🚀 Mirage模型能够实时生成UGC视频,无需依赖预录素材或传统工具。
🎭 生成的角色面部表情与肢体语言真实度极高,难以分辨真假。
🌍 支持29种语言生成视频,极大简化视频制作流程,降低成本与时间。
详情链接:https://www.captions.ai/mirage
12、谷歌推机器人控制模型Gemini Robotics,让机器人像人类一样思考行动
谷歌的Gemini Robotics是一个革命性的机器人控制模型,旨在将人工智能的智慧注入机器人,使其在物理世界中更智能地行动。基于Gemini2.0模型,Gemini Robotics具备强大的多模态理解能力,能够理解文本、图像、音频和视频,并具备出色的泛化能力,能快速适应新环境和指令。
【AiBase提要:】
🚀 Gemini Robotics基于Gemini2.0模型,具备强大的多模态理解能力,能够处理文本、图像、音频和视频。
🧠 该模型展现出卓越的泛化能力,能够迅速适应新物体和环境,解决各种实际问题。
🔒 谷歌在安全性方面采取了全面措施,确保机器人在执行任务时的安全性和可靠性。
详情链接:https://deepmind.google/discover/blog/gemini-robotics-brings-ai-into-the-physical-world/
13、智谱AI宣布再获珠海5亿元融资
珠海华发集团近期宣布向智谱公司投资5亿元人民币,旨在推动其GLM大模型的技术创新与生态发展。这一举措标志着珠海国资正式加入智谱的投资阵容。智谱在融资方面表现优异,去年成功完成多轮融资,总额超过40亿元,吸引了多家知名投资机构。
【AiBase提要:】
💡 珠海华发集团向智谱进行5亿元战略投资,支持其技术创新与生态发展。
🚀 智谱在融资方面表现强劲,去年完成超过40亿元的多轮融资,投资者涵盖多个城市的国资力量。
🌐 预计到2025年,智谱将推出全新开源大模型,推动AI行业的繁荣与发展。