


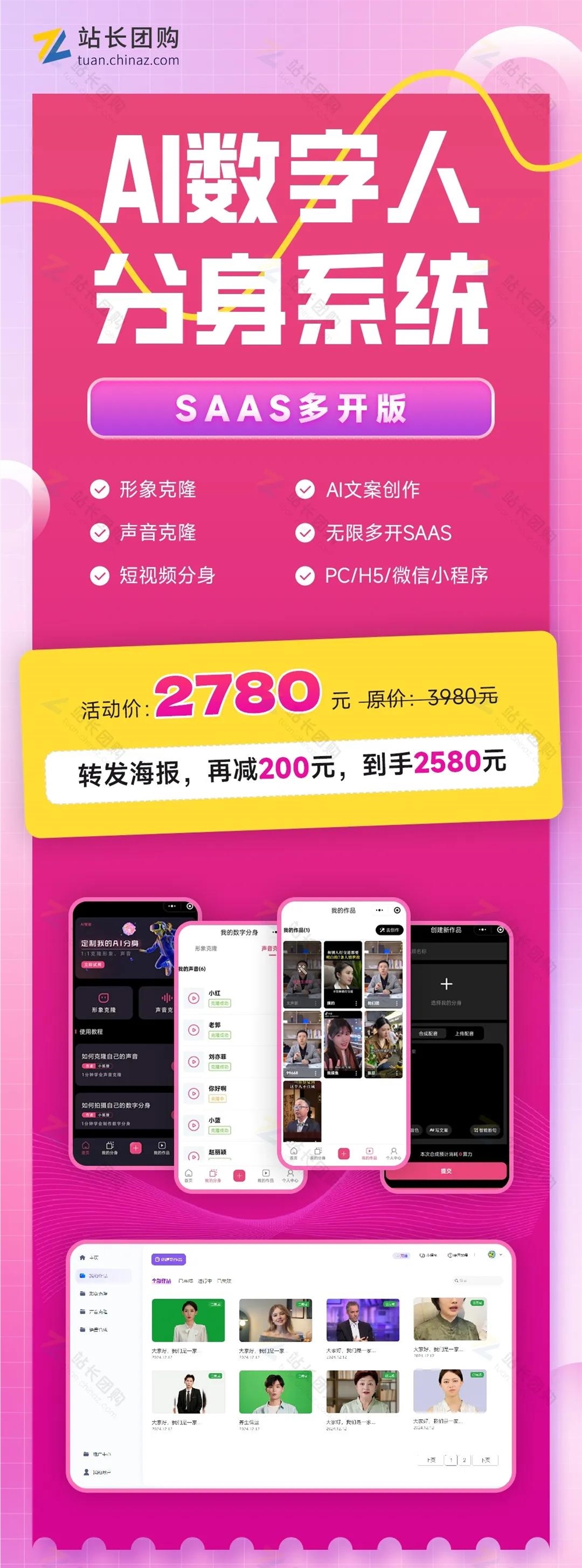
效果展示
核心功能:
1、形象克隆
轻松创建你的AI虚拟数字人!只需上传一段视频,即可高品质、批量克隆你的形象!如:
2、声音克隆
仅需1句话,快速克隆你的音色,高度还原真人音色,配合文案即可生成专属口播语音!
3、短视频分身
根据提示词,输入对应文案(或让AI自动生成),系统就可以根据你之前克隆的形象和声音,自动生成出对应的短视频分身出来。如:
4、多端支持
系统已上线PC前端功能。实现了PC/H5/微信小程序三端数据同步的功能。
(举报)
在2025年中国国际高新技术成果交易会上,邦彦技术股份有限公司发布NuwaAI V1.0,实现"一句话生成可执行任务的数字人"核心功能。用户通过自然语言指令即可生成具备身份设定、表达能力和完整任务执行流程的数字人,覆盖教育、商业、媒体等场景。该系统支持自动规划内容结构、协调节奏,并能执行发布会主持等全流程工作,标志着数字人从"内容展示"向"任务执行体"的重要转变,为行业提供可持续的生产力工具。
「现在是西天取经的第996天,刚把师父从妖怪嘴里救出来,师父身上都还是热乎的,我们就马不停蹄开始出发了。」在抖音,都能看到《西游记》里师徒四人的取经vlog了。 采访高考完刚出考场的爱因斯坦、孟德尔、门捷列夫;慈溪逛颐和园Vlog、大禹治水现场直播,各种AI生成的视频成为网友「玩梗搞抽象」的核心生产力。 尽管在专业影视
在今日盛大举行的百度世界大会上,百度公司宣布了一项重大举措——“罗永浩”同款慧播星高说服力数字人技术正式向全球开放。百度创始人李彦宏在大会上强调,数字人技术并非简单的应用工具,而是AI时代的一种基础性技术,甚至可能成为全新的通用交互界面,引领未来人机交互的新潮流。 据百度公布的数据显示,在今年双 11 购物节期间,慧播星数字人带货成绩斐然,
英特尔联合豆包-应用生成发起“一点都不技术”创作挑战赛,旨在通过零代码AI工具降低创意门槛。用户只需输入一句话或一张图,即可在5分钟内生成网页、工具或小游戏等多样化作品。赛事设置总价值20万元奖励,包含现金及火箭发射观礼等特色福利,并构建“创作-交流-成长”的完整生态,推动AI技术普惠。活动将持续至2025年12月8日,让每个平凡创意都有机会落地生花。
微信宣布小程序将在iOS端支持虚拟支付,标志着其在苹果平台发展进入新阶段。微信欢迎苹果对开发者的支持,并对苹果推出的小程序合作伙伴计划持积极态度。该计划将符合条件的iOS小程序内购佣金率从30%降至15%,旨在平衡平台与开发者利益。苹果与腾讯就微信小程序内购分成达成共识,此举将增加开发者收入、丰富平台内容,为用户带来更优质体验,同时为行业处理平台与开发者关系提供新范本。
汶上县应急指挥中心由ITC保伦股份携手打造,现已全面投入使用。该中心整合了公安、水务、气象等20多个部门的视频信号,实现八大功能“一张图、一个网、一键操作”,显著提升了全县风险应对能力。系统采用LED显示屏、数字会议、专业扩声等先进设备,构建了智能可视化应急管理平台,支持多平台信息联动与远程视频会商,助力形成统一指挥、反应灵敏的应急体系,并荣获省级先进荣誉,为公共安全治理现代化提供了有力技术支撑。
逗哥配音作为领先AI配音平台,以“海量音色+AI赋能”为核心,拥有上千款声音类型,覆盖多语言及商业场景。通过自研大模型韵律技术,实现情感饱满的语音生成,支持影音解说、小说推文等多种需求。平台内置场景化音色模板,新手也能快速制作专业配音,免费功能已满足日常短视频创作。其AI分角功能优化多人角色管理,提升对话内容制作效率。逗哥配音正重塑语音创作边界,成为短视频解说领域首选工具。
全球顶级视觉特效公司数字王国计划联合多家国际企业,在上海打造以人工智能为技术支撑、融合多个国际知名IP的综合性文旅项目。该公司拥有30年虚拟人、视觉特效技术积累,曾获奥斯卡奖项,并开发虚拟人邓丽君等经典IP。项目将结合VR/AR/MR技术,推出沉浸式体验,并计划引入好莱坞电影IP及中国原创文化内容,构建全球化沉浸体验空间。此举旨在推动科技与文化融合,助力上海静安、杨浦两区打造城市新地标与文旅新生态。
中国移动宣布北斗短信息服务完成重大升级,新增图片、语音等富媒体功能,文本传输能力显著提升,单条消息可发送40个汉字、接收达10个汉字。Redmi Note 15 Pro+卫星消息版率先支持升级,其他品牌终端也将陆续开启。此次升级在无地面网络信号时仍能通过多种形式传递信息,为户外探险、应急救援等场景提供坚实通信保障,标志着北斗通信正式步入“视听兼具”新时代。
小米双11战报显示,截至11月11日,全渠道支付额突破290亿元。雷军发文感谢消费者支持。活动期间累计让利20亿元,覆盖手机、数码、家电等全品类产品。手机方面,Redmi K80至尊版起售价降至2399元;小米平板7 Ultra直降500元后5199元起。家电领域,小米电视S Pro 85 Mini LED 2026款与米家冰箱Pro优惠达1600元,米家三区洗衣机Pro最高可省1000元。数据印证小米“手机×AIoT”战略成功,智能家居生态获市场广泛认可。