
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
新鲜AI产品点击了解:https://top.aibase.com/
1、Qwen2-Audio:千问系列的音频多模态模型 无需文字即可语音交互
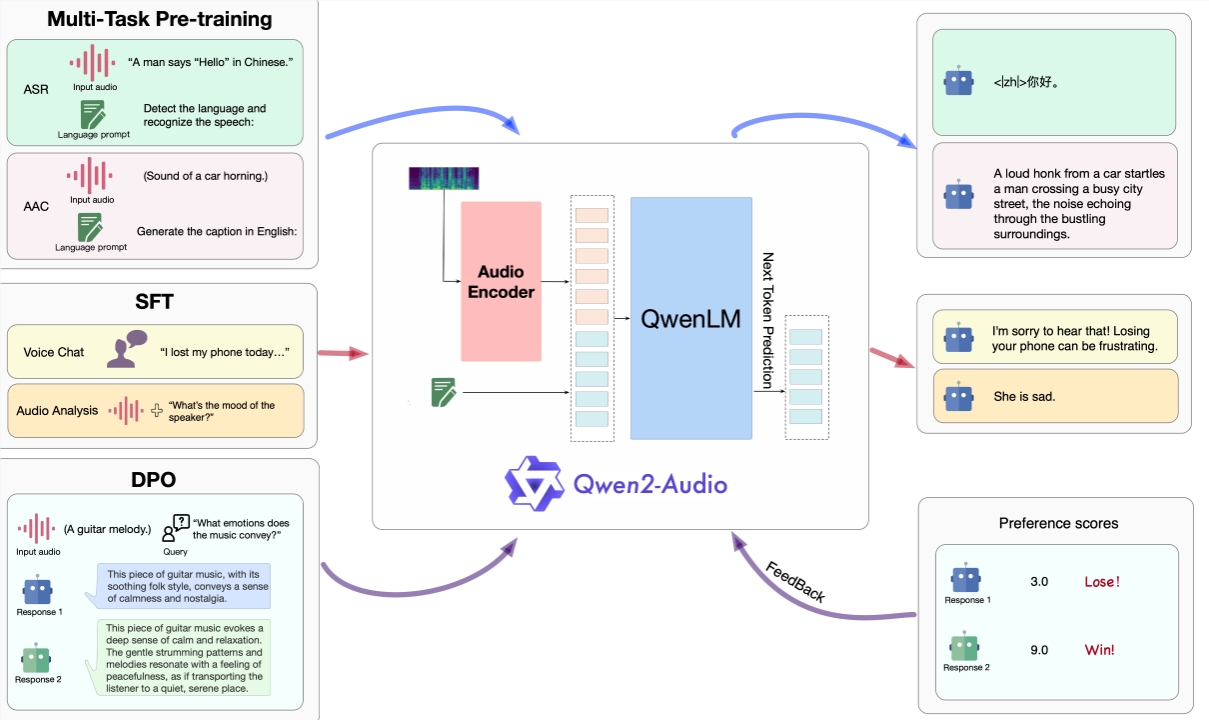
阿里云最新发布的 Qwen2-Audio 大规模音频语言型模型,革新了语音交互体验,用户无需输入文字即可与其进行语音交互,提供更便捷的体验。模型能智能理解音频内容并按语音命令响应,在音频中表现优异。Qwen2-Audio 是开源的,旨在促进多模态语言社区的进步。
【AiBase提要:】
🌟 Qwen2-Audio 提升了语音交互体验,可接受多种音频信号进行分析或回答指令,拓展了语音交互功能。
🌟 模型在音聊天和音频分析方面提供了独特的交互模式,用户体验更加便捷。
🌟 Qwen2-Audio 在音频中智能理解内容,对语音命令做出适当响应,优于以往的性能表现。
详情链接:https://top.aibase.com/tool/qwen2-audio
2、又搞了个大的!Mistral AI发布数学模型MathΣtral
Mistral AI团队发布了名为MathΣtral的数学模型,这是对阿基米德2311周年的致敬,也是数学推理和科学发现领域的重大突破。该模型专为数学推理和科学发现设计,拥有32k的上下文窗口,能处理更长、更复杂的数学问题。开源于Apache2.0许可下,为学术界和开发者提供便利。

【AiBase提要:】
🌟 MathΣtral是7B模型,具有32k的上下文窗口,处理更长、更复杂的数学问题。
🔍 在STEM领域的专业特长,在各种行业标准基准测试中达到了同类别的先进推理能力。
💡 MathΣtral通过更多的推理时间计算,在MATH基准测试中获得高分,证明了推理能力的重要性。
详情链接:https://mistral.ai/news/mathstral/
3、数学难题暴露AI短板:13.11>13.8冲上热搜,所有LLM的致命弱点被揭开!
这篇文章讨论了一个简单的数学问题引发的AI处理常识性问题能力的讨论,揭示了大型语言模型在数值比较任务上可能遇到的困难。文章指出AI在处理基本数学运算和逻辑推理方面仍存在局限性,需要改进训练数据、Prompt设计以及数值处理准确性和逻辑推理能力。


【AiBase提要:】
🤖 AI处理常识性问题能力受限,13.11>13.8数学难题暴露了AI短板。
📊 训练数据偏差、浮点精度问题和上下文理解不足是AI在数值比较任务上可能遇到的困难。
💡 改进AI需优化训练数据、Prompt设计、数值处理准确性和逻辑推理能力,以提高处理常识性问题的能力。
文章详情:https://www.chinaz.com/ainews/10269.shtml
4、百度网盘推出AI英语学习工具盘盘单词
百度网盘推出了名为「盘盘单词」的全球首个结合个人照片场景与英语学习的AI工具,旨在解决传统英语学习中的记忆困难和表达问题。用户可通过照片呈现单词和场景化内容,创造熟悉的英语环境,使学习更有趣有效。工具提供专属AI语音风格,如“马x克”、“meimei”教授英语,支持个性化复习计划。利用图像分析技术结合用户生活场景,提高学习实用性和相关性。

【AiBase提要:】
📱 利用个人照片场景与英语学习结合,创造熟悉的学习环境。
🎤 提供专属AI语音风格,如“马x克”、“meimei”教授英语,增强学习体验。
📊 通过优化学习算法,提供个性化复习计划,确保学习内容与用户需求匹配。
5、智源研究院推出新一代无编码器视觉语言多模态大模型EVE
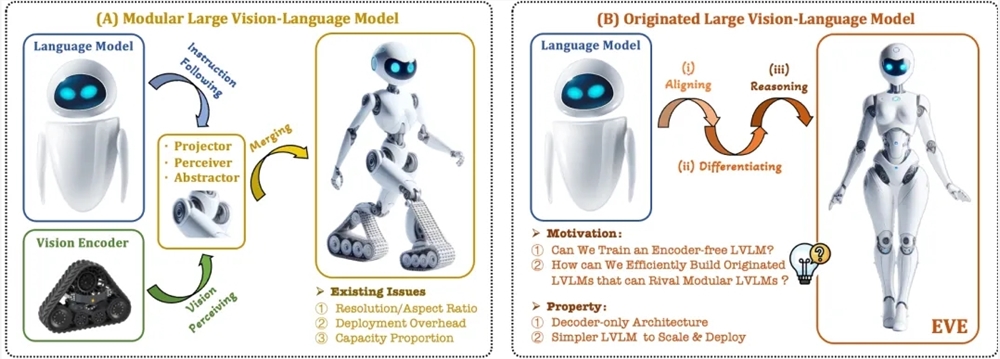
近期,智源研究院联合大连理工大学、北京大学等高校推出了新一代无编码器的视觉语言模型EVE,通过精细化训练策略和额外的视觉监督,解决了多模态大模型训练分离导致的视觉归纳偏置问题,表现优异于基于编码器的主流多模态方法。EVE展示了无编码器原生视觉语言模型的潜力,为多模态模型的发展提供了新思路。
【AiBase提要:】
🔍 EVE采用无编码器架构,处理任意图像长宽比,表现优异于同类型模型。
📊 EVE使用公开数据预训练,训练时间短,数据和训练代价低。
🚀 EVE提供透明高效的探索路径,在多个视觉-语言基准测试中表现优异。
详情链接:https://arxiv.org/abs/2406.11832
6、可在手机运行!Hugging Face推小语言模型SmolLM 低参数表现优秀
Hugging Face推出了SmolLM,一款小型语言模型系列,参数从135M到1.7B不等,适用于各种设备,表现出色且保护用户隐私。
【AiBase提要:】
🚀 高效性能: SmolLM模型在低计算资源下表现出色,保护用户隐私。
📚 丰富数据: 使用高质量的SmolLM-Corpus数据集,确保模型学习到多样知识。
💻 多种应用: 适用于手机、笔记本等设备,灵活运行,满足不同需求。
详情链接:https://top.aibase.com/tool/smollm
7、前OpenAI和特斯拉顶尖工程师创办AI原生学校Eureka Labs
作为一名学习者,我对安德烈·卡尔帕西创办的Eureka Labs感到兴奋和期待。这所学校将教师与AI相结合,提供高效的学习体验,让学习变得更加有趣和便捷。
【AiBase提要:】
🌟 Eureka Labs实现“教师+AI”协同教育,提供专家编写的课程材料,并由AI助手引导学生学习。
📚 首个产品“世界上最好的AI课程”LLM101n将帮助学生训练自己的AI,计划包括线上和线下课程。
🌍 卡尔帕西希望教育内容可免费获得,未来通过举办课程收取费用,实现可持续发展。
详情链接:https://top.aibase.com/tool/eureka-labs
8、字节跳动本周将公布文生图、类sora新视频等全新AI模型技术进展
字节跳动团队计划于7月19日首次大范围公布最新人工智能模型技术进展,展示创新技术在长视频和高动态方向上的应用,将直接对标OpenAI的Sora文生视频模型。公司将AI大模型列为P0最高级别战略方向,抖音、剪映等团队也在研发AI视频模型应用。这一举动凸显了字节跳动在AI领域的雄心,引领全球AI竞争新局面。
【AiBase提要:】
🚀 字节跳动计划公布最新人工智能模型技术进展,包括文生图、类Sora新视频等全新AI模型。
💡 公布的内容将展示在长视频和高动态方向上的创新技术,直接对标OpenAI的Sora文生视频模型。
💥 字节跳动将AI大模型列为集团P0最高级别的战略方向,多内部团队积极研发AI视频模型应用,预计近期公布成果。
9、Runway iOS客户端重大更新 手机上也可以使用Gen3 模型了
Runway的iOS客户端迎来了重大更新,现在,苹果用户也能在手机上体验到Gen3模型的强大功能。这一更新不仅是对用户体验的提升,更是Runway在AI视频生成领域的一次飞跃。
【AiBase提要:】
✨ Gen3模型功能强大,提升用户体验,标志着Runway在AI视频生成领域的飞跃。
🚀 Gen3模型在保真度、一致性和动作表现上有显著提升,为通用世界模型构建迈出坚实一步。
🎨 Gen-3Alpha支持多种生成工具,包括文本到视频、图像到视频、文本到图像转换,为创作者提供丰富创作选择。
详情链接:https://apps.apple.com/us/app/runwayml/id1665024375
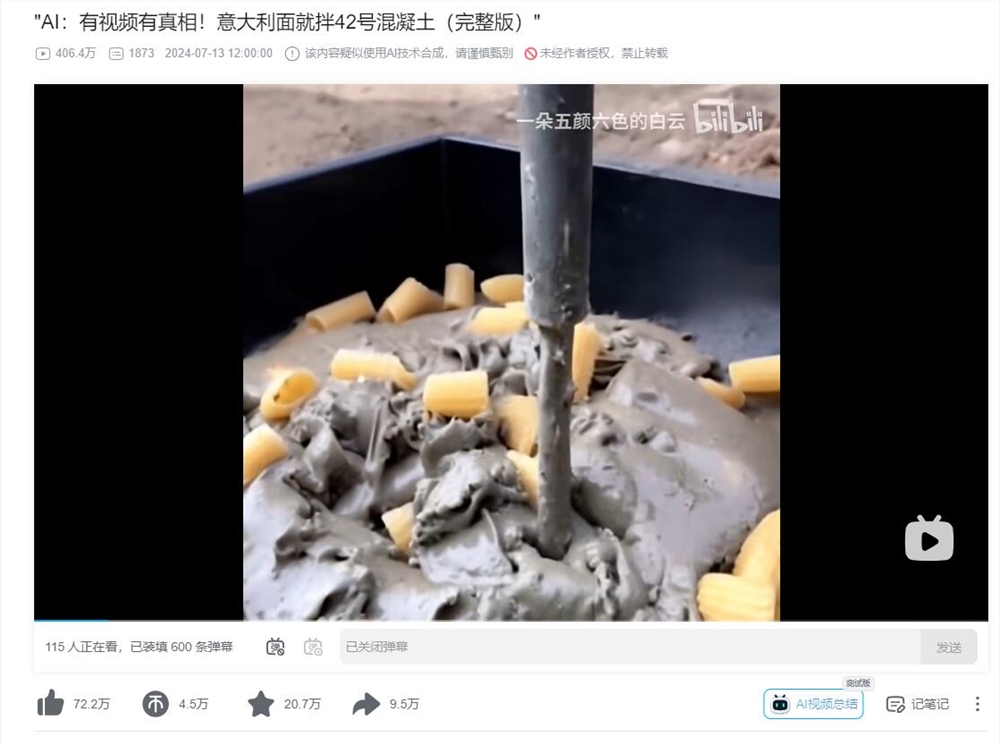
10、AI表演抽象艺术意大利面拌 42 号混凝土 网友CPU差点烧了
在当前的AI技术热潮中,视频生成领域的创新应用日益丰富。一种能将抽象概念转化为视觉内容的AI工具备受关注,展现出幽默与深思并存的创意。AI技术赋予了经典台词新生命,延伸出令人捧腹的幽默场景,展示了理解情感和扩展创意的能力。AI正在深入娱乐领域,成为理解人类情感和创造力的工具,展示了与人类创意结合的无限可能。
【AiBase提要:】
⚙️ AI工具将抽象概念转化为视觉内容,创造幽默与深思并存的创意。
🎭 AI赋予经典台词新生命,延伸出幽默场景,展示理解情感和扩展创意的能力。
🔮 AI深入娱乐领域,成为理解人类情感和创造力的工具,展示与人类创意结合的无限可能。
详细内容:https://www.chinaz.com/ainews/10249.shtml
11、温柔御姐在线安抚!EmoLLM:一个用于心理健康领域的大模型项目
在当今快节奏的社会中,心理健康问题备受关注。EmoLLM作为一个专注于心理健康辅导的大型模型项目,为用户提供深度的心理支持,注入新活力并提升心理韧性。
【AiBase提要:】
🧠 EmoLLM利用AI技术为用户提供全面、科学、易用的心理健康辅导工具。
💬 EmoLLM功能覆盖心理健康评估、情绪管理、认知行为辅导、行为模式改善、社会支持系统、心理韧性提升和预防干预措施。
🔄 EmoLLM提供多轮对话支持,模拟真实场景对话,提供持续心理辅导和个性化心理健康干预方案。
详情链接:https://top.aibase.com/tool/emollm
12、理想汽车成立端到端自动驾驶团队
理想汽车近期在智能驾驶领域进行组织结构调整,成立了专门的"端到端自动驾驶"实体组织,展现对自动驾驶技术的重视和投入。该举措符合行业趋势,显示出理想汽车在智能驾驶领域的战略布局和发展方向。
【AiBase提要:】
🚗 理想汽车成立专门的"端到端自动驾驶"实体组织,团队规模约200人,展现对自动驾驶技术的重视。
🔬 理想汽车智能驾驶团队总体约800人,主要分为算法研发和量产研发两大组,展示了在智能驾驶技术上的创新思路。
🔧 理想汽车智能驾驶研发体系由贾鹏和王佳佳领导,形成完整的智能驾驶研发体系,有助于提升技术实力和产品竞争力。
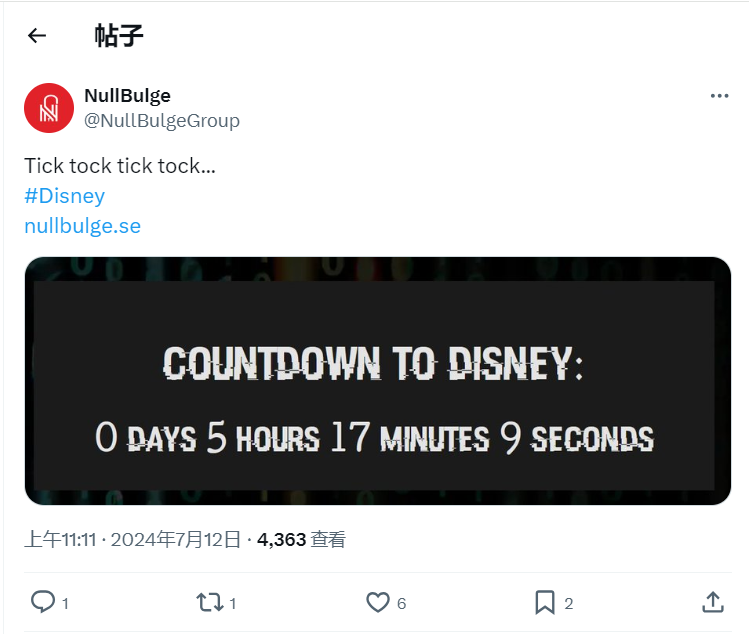
13、行为艺术!黑客窃取超过1TB迪士尼内部数据
黑客组织NullBulge成功入侵迪士尼内部通讯平台,窃取超过1TB数据,抗议迪士尼对艺术家的立场。他们声称保护艺术家权利,未要求赎金。入侵方式是通过游戏修改工具。
【AiBase提要:】
💾 黑客组织NullBulge窃取1TB迪士尼数据,抗议公司对艺术家立场。
🔍 目标是保护艺术家权利,确保公平报酬,未要求赎金。
🎮 通过游戏修改工具入侵迪士尼网络,发布泄露数据。
14、Haiper AI更新视频模型 可生成 8 秒视频并大幅提升质量
Haiper AI最近更新了视频模型,用户现在可以生成8秒时长的视频,并通过超分工具提升视频分辨率。这一更新让用户能够创作更加复杂和丰富的故事线,增加内容吸引力。虽然视频效果不错,但Haiper AI的视频生成并非使用DIT架构,无法模拟物理世界规律。
【AiBase提要:】
🔑 免费体验: 用户可以免费体验Haiper AI的功能,降低了尝试新技术的门槛。
🔧 多功能支持: Haiper AI支持文本转视频、图生视频、视频转视频等,提供视频卡通化、照片卡通化和视频重绘等功能,满足不同场景需求。
🎥 视频创作功能: 文本转视频简化视频制作流程,图片动画增强视觉吸引力,视频重绘个性化视频,导演视角提供高级选项,增加创作灵活性和深度。
详情链接:https://top.aibase.com/tool/haiper
15、小冰AI数字员工升级:发布全新“零样本”技术、超千亿大模型基座
小冰公司最近宣布了其AI数字员工产品线的全新升级,旨在进一步丰富产品并提升实时交互效果。新技术包括“零样本”数字人技术、超千亿大模型基座和透影音画传输系统,展现了小冰公司在数字人领域的技术创新和发展动力。

【AiBase提要:】
🚀 Z-XNR技术实现高质量形象声音复刻,保持数字人视觉个性化表达。
💡 超千亿大模型基座与Agent构建框架提升数字员工交互精准度。
🔗 透影音画传输系统确保声音画面同步,提供高质量低延迟的音画传输。
(举报)