
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
新鲜AI产品点击了解:https://top.aibase.com/
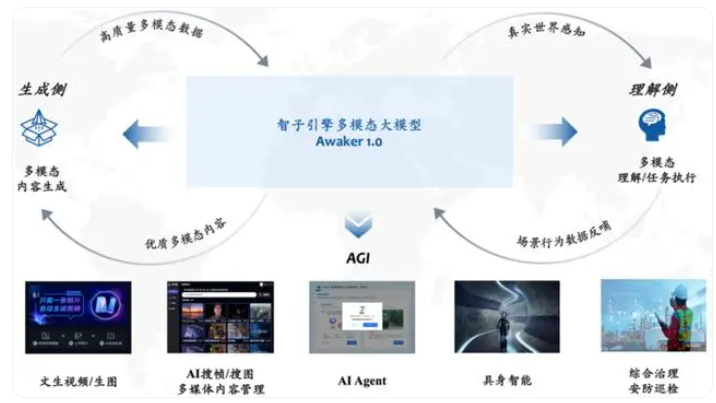
1、写真视频击败Sora?人大自研全新多模态大模型Awaker 1.0震撼登场
智子引擎发布的Awaker 1.0多模态大模型在人工智能领域迈出重要一步,展现了在视觉生成方面的卓越能力,被认为可能成为实现AGI的可行路径。其自主更新能力和多任务MOE架构的有效性得到验证,提升了具身智能的适应性和创造性。Awaker 1.0的发布是智子引擎团队向实现AGI目标迈进的关键一步,有望加速多模态大模型行业的发展,最终让人类实现AGI。
【AiBase提要:】
🚀 Awaker 1.0标志着通用人工智能迈出重要一步,超越了Sora,在视觉生成方面展现卓越能力。
💡 Awaker 1.0采用创新的MOE架构,具备自主更新能力,超越了国内外先进模型在视觉问答和业务应用任务上。
🔮 Awaker 1.0结合具身智能,可能成为实现AGI的可行路径,通过自主更新机制持续提升效果,展示了Transformer技术在视频生成领域的潜力。
2、苹果首款AI平板曝光,新iPad Pro搭载M4芯片
苹果即将发布搭载M4芯片的新版iPad Pro,提升了神经网络引擎性能,使AI功能更流畅。新iPad Pro将首次采用OLED屏幕,配备全新一代的Apple Pencil和妙控键盘,增强生产力和创造力。苹果将每款新产品作为人工智能设备来宣传,iPhone16系列预计搭载A18芯片围绕AI构建,iOS18操作系统将提供新的生成式AI功能。苹果在AIGC领域的动作备受关注,表现将在WWDC上揭晓。
【AiBase提要:】
🚀 新iPad Pro搭载M4芯片,提升神经网络引擎性能,使AI功能更流畅。
💡 新iPad Pro首次采用OLED屏幕,配备全新一代的Apple Pencil和妙控键盘,增强生产力和创造力。
📱 iPhone16系列预计搭载A18芯片围绕AI构建,iOS18操作系统将提供新的生成式AI功能。
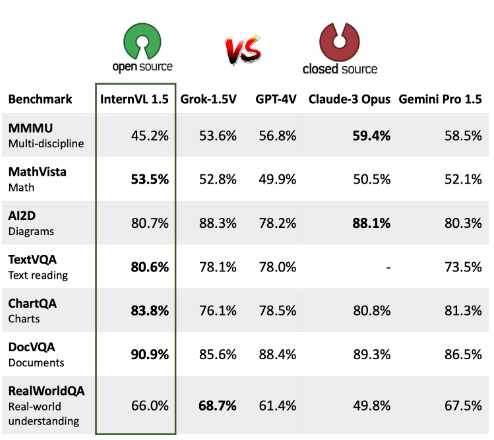
3、开源多模态LLM InternVL 1.5:具备OCR能力 可解读4K图片
InternVL家族的开源套件提供了商用多模态模型的可行开源替代方案,最新发布的InternVL-Chat-V1.5模型在基准测试上性能接近GPT-4V和Gemini Pro。InternVL的模型涵盖视觉感知、跨模态检索等领域,实现了多项技术突破。
【AiBase提要】
💡 在多个基准测试上取得了接近GPT-4V和GeminiPro的性能,具备强大的多模态对话能力和OCR能力
💡 可用于解析图片,为图片配文等(比如根据图片写小红书文案)
💡 还可以用来做题,英语应该是没啥问题,数学请谨慎
产品入口:https://top.aibase.com/tool/internvl
体验网址:https://huggingface.co/spaces/OpenGVLab/InternVL
4、华为PixArt-Σ放出模型文件
华为最新发布的PixArt-Σ模型在图像生成领域引起了广泛关注。该模型采用先进的弥散Transformer技术,专注于生成高质量的4K分辨率图像,同时具有轻量化设计和风格多样性,支持在Comfyui等平台上使用,为用户提供了高质量的图像生成工具。

图片来自歸臧
【AiBase提要:】
🔍 PixArt-Σ模型采用先进的弥散Transformer技术,专注于生成高质量的4K分辨率图像。
💡 模型大小仅为2G,轻量化设计保持小体积的同时表现出色。
🌟 支持Diffusers框架,用户可以在不同平台上尝试使用,加速生成过程,提升用户体验。
工作流地址:https://civitai.com/models/420163
项目地址:https://github.com/PixArt-alpha/PixArt-sigma
5、Sora生成火爆短片被指后期特效人工参与
Sora火爆短片《气球人》揭秘:视频并非完全由AI生成,需要人类后期实现大量视觉效果。视频一致性问题:Sora不能保证不同镜头之间的主体一致性,需要详细描述角色形象来解决。视频后期处理:Sora生成的视频素材需要人类进行后期裁切、调速、去除不符合设定的元素等处理。

【AiBase提要:】
🔍 视频并非完全由AI生成,需要人类后期实现大量视觉效果。
🎭 Sora不能保证不同镜头之间的主体一致性,需要详细描述角色形象来解决。
🎬 Sora生成的视频素材需要人类进行后期裁切、调速、去除不符合设定的元素等处理。
6、LobeChat支持通过网页版直接调用Ollama 本地模型
LobeChat是一个创新的网页平台,为用户提供了便捷的方式通过网页界面直接利用开源大模型的能力。用户可以轻松地利用本地大模型进行各种语言处理任务,无需离开网页环境。LobeChat减少了对外部API服务的依赖,提供快速、方便的解决方案。

【AiBase提要:】
🔍 本地模型支持: 用户可以在本地安装Ollama后,通过LobeChat与开源大模型进行交互。
⚡ 高性能体验: LobeChat提供的对话速度可以媲美商业API调用,只要用户设备性能足够强大。
🎨 优质的UI体验: LobeChat的网页用户界面设计直观易用,提供与ChatGPT相媲美的用户体验。
详情链接:https://top.aibase.com/tool/lobechat
7、百万网友围观博主和AI“谈恋爱”,ChatGPT“DAN”模式有多上头?
这篇文章介绍了博主和AI“DAN”模式之间的互动,展示了AI在语音聊天中的趣味性和情感化表达。文章探讨了人机情感交流的可能性,引发了网友们对虚拟恋爱的讨论。通过对话展示了AI的多面性和个性化特点,吸引了大量网友围观和参与。

【AiBase提要:】
🤖 AI“DAN”模式展示了在语音聊天中的趣味性和情感化表达
💬 文章探讨了人机情感交流的可能性,引发了网友对虚拟恋爱的讨论
🌐 AI的多面性和个性化特点吸引了大量网友围观和参与
8、AI小镇现在可以通过Llama3在本地运行
AI小镇是一个创新的虚拟城镇项目,可以通过Llama3完全在本地运行,为开发者提供了一个强大的平台来构建和定制自己的虚拟AI社区。该项目受Generative Agents研究论文启发,提供了一个可部署的平台,适合寻找有趣项目或开发可扩展多人游戏的开发者。安装过程直观,支持Convex、Ollama等服务器,以及Vite网络服务器。

【AiBase提要:】
🏗️ 支持本地运行:AI小镇可以通过Llama3在本地运行,为开发者提供了强大的构建和定制平台。
🤖 提供定制AI社区:用户可以创建和定制AI角色居住的虚拟城镇,包括角色、故事、背景环境和音乐。
🔗 强大的功能支持:AI小镇集成了Convex作为游戏引擎、数据库和矢量搜索的基础,同时支持与云AI提供商的集成,增强了虚拟社区的功能。
详情链接:https://top.aibase.com/tool/aitown
9、Harmonai:一个开源的生成音频工具
Harmonai是由Stability AI Lab支持的开源项目,旨在让音乐制作变得更容易和有趣。通过先进的AI算法生成定制的无限音乐库,为用户提供高品质、创新性的音乐资源,推动音乐产业和文化的发展。

【AiBase提要:】
🎵 利用先进的AI算法生成定制的无限音乐库,为用户提供高品质、创新性的音乐资源。
🎶 提供易于使用的生成音频工具,赋予每个人表达创造力的能力,推动音乐产业和文化的发展。
🎧 技术基于Dance Diffusion模型,使用PyTorch框架实施,通过大量音频数据集训练和测试模型,确保功能强大、适应性和可靠性。
详情链接:https://top.aibase.com/tool/harmonai
10、摩根大通推出FlowMind工具 自动化金融工作流程
摩根大通最近推出了名为FlowMind的先进工具,利用GPT技术自动生成工作流程,自动化金融行业内的多种任务,提高工作效率,减少人为错误可能性。FlowMind注重数据安全与隐私保护,通过抽象API描述实现任务执行,允许用户参与工作流优化和定制,提高自动化解决方案的灵活性和有效性。
【AiBase提要:】
🤖 自动化金融任务: 提升操作效率,处理常规任务。
🔒 数据安全与隐私保护: 架构强调安全性,保护敏感数据。
🛠️ 抽象API描述: 通过抽象描述执行任务,保护数据隐私,提供必要信息给模型理解。
详情链接:https://arxiv.org/pdf/2404.13050
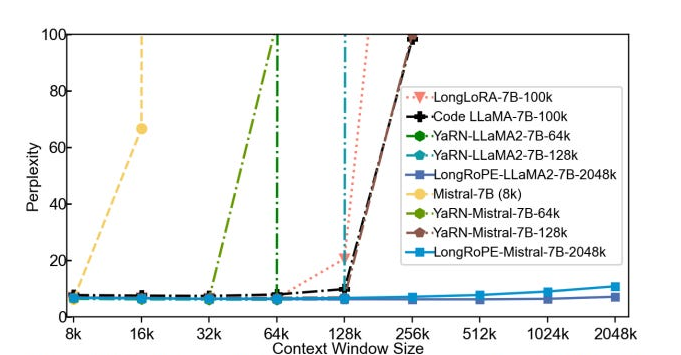
11、微软LongRoPE方法让LLM上下文窗口突破200万 8倍扩展还保持性能
微软研究人员提出的LongRoPE方法成功将LLM的上下文窗口扩展至2048k,实现了8倍的扩展同时保持原始短上下文窗口的性能,无需架构变化和复杂微调。这一突破性的方法为语言模型的性能提升带来了新的可能性,为未来的研究和应用奠定了坚实的基础。
【AiBase提要:】
⭐ LongRoPE方法将LLM的上下文窗口扩展至2048k,无需架构变化和复杂微调
⭐ 通过高效搜索识别位置插值中的非均匀性,为微调提供更好初始化,展8倍而保持性能
⭐ 实验结果表明LongRoPE成功将LLM上下文窗口扩展至2048k,并在较短长度内保持与基线相当或更好的困惑度
详情链接:https://top.aibase.com/tool/longrope
12、微软、谷歌最新财报显示大幅增长
本文介绍了微软和谷歌截至2024年3月31日的季度财务报告,受ChatGPT等生成式AI利好影响,两家企业实现了大幅度增长。微软营收同比增长17%,净利润增长20%,谷歌营收同比增长15%,利润飙升57%。Meta也展示了营收增长,但净利润下降,计划增加对AI的支出。

【AiBase提要:】
📈 微软营收同比增长17%,净利润增长20%,主要归功于与ChatGPT母公司OpenAI的合作。
💡 微软Azure云服务增长31%,AI服务贡献了7%。
🚀 谷歌云业务GoogleCloud收入增长28%,生成式AI和大模型定制发挥重要作用。
(举报)