
当企业真正要接入大模型能力时,技术负责人常陷入两难:
“国际大厂的Gemini技术先进,但国内新锐的DeepSeek性价比突出,到底该怎么选?”
参数对比表格?技术白皮书?这些看似专业的资料,往往离真实决策场景相去甚远。作为国内首个专注LLM横向评测的中立平台,AIbase.cn用真实数据告诉你:模型选型,本质是场景与成本的精准匹配。
一、抛开参数迷雾,聚焦四大决策维度
在AIbase的对比体系中(https://model.aibase.cn/compare),我们始终围绕直接影响业务落地的核心指标:
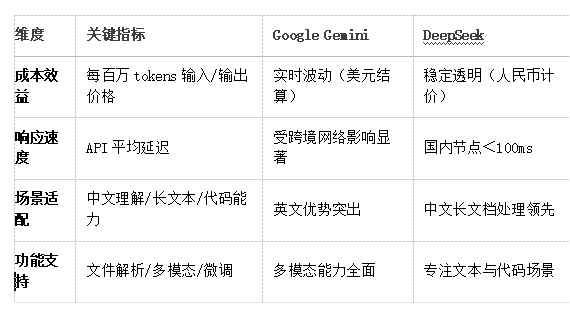
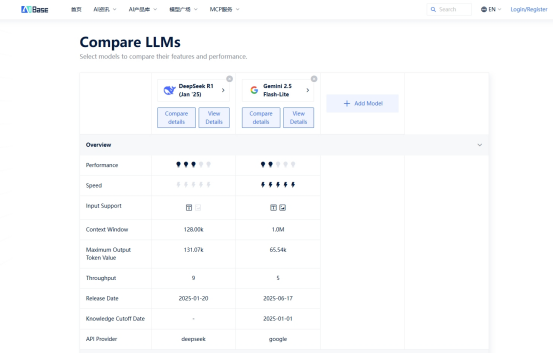
二、真实场景下的模型对决
▶ 场景A:跨境电商客服系统
需求痛点:多语言实时翻译+ 海外用户咨询处理
AIbase选型建议:
Gemini在多语言混合场景下识别准确率提升12%(平台实测数据)
但需警惕:跨境API延迟可能导致客服响应超时
决策关键:在AIbase设置「多语言支持」+「响应速度<200ms」筛选器
▶ 场景B:金融研报智能分析
需求痛点:百页PDF解析 + 中文关键信息提取
AIbase数据揭示:
DeepSeek支持128K超长上下文,处理复杂文档结构更稳定
相同分析任务成本仅为Gemini的1/3(人民币计价优势)
决策关键:使用平台「上下文长度」排序+「中文文档处理」评分维度
三、为什么技术总监都在用AIbase?
当某智能硬件公司CTO在周会上被问:“为什么最终选DeepSeek而不是Gemini?” 他打开AIbase对比页展示:
1.成本可视化:接入量预估工具显示,月均1000万tokens场景下,DeepSeek可节省47%成本
2.性能可验证:中文常识推理测试集得分,DeepSeek比Gemini高9.3个百分点
3.决策可追溯:所有对比数据标注来源(官方文档/第三方评测/平台实测)
“当你能用三分钟说清楚为什么选A而不是B,技术决策就不再是玄学。”
四、你的业务更适合谁?
通过AIbase的多维度动态筛选器,可快速定位适配模型:
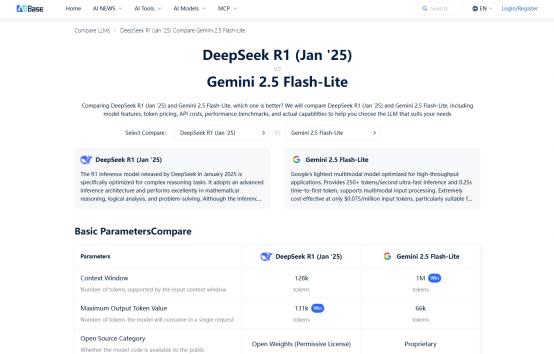
✅优先考虑Google Gemini当:
业务面向全球多语言用户
需要图像/语音多模态能力
已有Google Cloud技术栈
✅优先选择DeepSeek当:
核心场景为中文文本处理
需解析超长技术文档/合同
对API成本敏感且需稳定延迟
立即体验精准选型:
访问AIbase基地 - 让更多人看到未来 通往AGI之路
3分钟生成你的专属选型报告
我们不做模型推销,只提供让你看清真相的标尺
——AIbase,让每个技术决策都经得起质疑
(举报)