
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
新鲜AI产品点击了解:https://top.aibase.com/
1、AI视频王者回归!Runway全新Gen3模型又让网友惊艳了一把
这篇文章介绍了Runway最近推出的新一代视频生成模型Gen-3Alpha,该模型在保真度、一致性和动作表现方面有重大改进,为构建通用世界模型迈出了重要一步。Gen-3Alpha具备多项显著功能和特点,成为创意产业中的新星。
【AiBase提要:】
⭐️ Gen-3Alpha在保真度、一致性和动作表现方面有显著提升,能够生成表达丰富的、逼真的人类角色
⭐️ Gen-3Alpha支持多种生成工具,如文本到视频、图像到视频、文本到图像转换工具。
⭐️ 能够进行精细时间控制,支持多种高级控制模式,包括运动画笔、先进摄像头控制和导演模式
⭐️ 极度稳定的光影,即便在高速移动的场景中也能保持高质量输出。
更多视频点此查看:https://mp.weixin.qq.com/s/5LbM0NfkeiYFU0r4VDqpYA
官网地址:https://top.aibase.com/tool/gen-3-alpha
2、Luma AI发布了 Extend 功能 视频时长扩充到10秒以上
Luma AI最近更新了Dream Machine视频模型,新增了Extend功能,可以将视频时长扩充到10秒以上,并保持原视频风格、人物对象一致。虽然Extend功能生成延长视频耗时较长,但风格一致性保持得很好。
【AiBase提要:】
✨ Dream Machine升级发布Extend功能,视频时长可达10秒以上,保持原视频风格与对象一致。
⏱️ 使用Extend功能延长视频耗时较长,但风格一致性良好。
🔗 详情:https://www.chinaz.com/ainews/9639.shtml
3、DeepSeek发布开源模型DeepSeek-Coder-V2
DeepSeek最近发布了开源模型DeepSeek-Coder-V2,该模型在代码和数学能力方面超越了GPT-4-Turbo,具有全球领先的性能。模型采用MoE架构,支持多语言和更长的上下文处理长度。用户可免费商用,无需申请。

【AiBase提要:】
🚀 模型性能全球领先,特别擅长代码生成和数学算术。
💡 支持338种编程语言和128K上下文长度,满足更多开发需求。
🔗 提供API服务,价格与DeepSeek-V2一致,在基准测试中表现优异。
详情链接:https://top.aibase.com/tool/deepseek-coder-v2
4、Adobe Acrobat迎来重大AI升级 支持多文档分析和图像生成
Adobe即将推出一系列重磅AI升级,提升Acrobat的AI助手功能、图像生成能力,保证数据隐私保护。这次更新将极大提升办公效率,为处理大量文档和优化视觉内容带来便利。
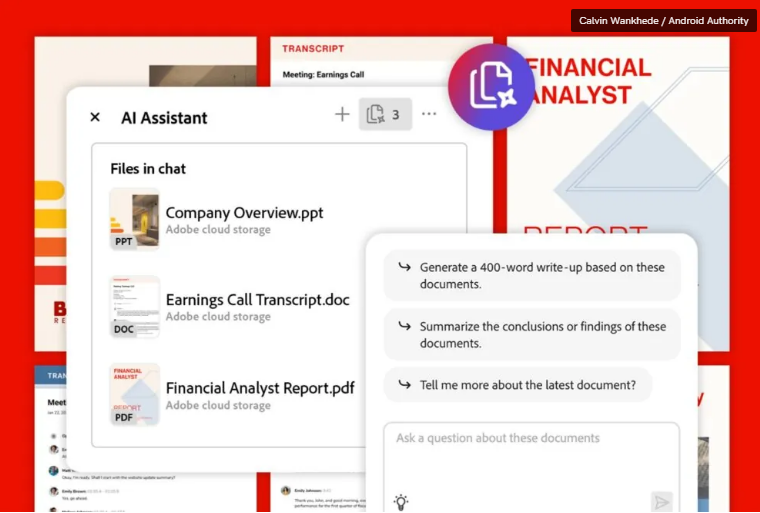
【AiBase提要:】
🚀 AI助手功能升级,支持多文档分析和查询,提升用户体验。
🖼️ 新增AI图像生成器,用户可生成全新图像或编辑现有PDF中的图像。
🔒 数据隐私保护承诺,文档上传至云端分析但不用于训练AI模型,禁止第三方利用。
5、苹果在Hugging Face平台发布20个Core ML模型
苹果在Hugging Face平台发布了20个新的Core ML模型和4个数据集,展示了其在推动AI发展方面的重大进展。这次更新不仅包括着眼于文本和图像的令人振奋的新模型,还涵盖了广泛的应用,如图像分类、单目深度估计和语义分割。苹果强调了设备AI的重要性,通过在用户设备上运行优化的模型,提升了应用程序性能,同时保障用户数据安全和隐私。
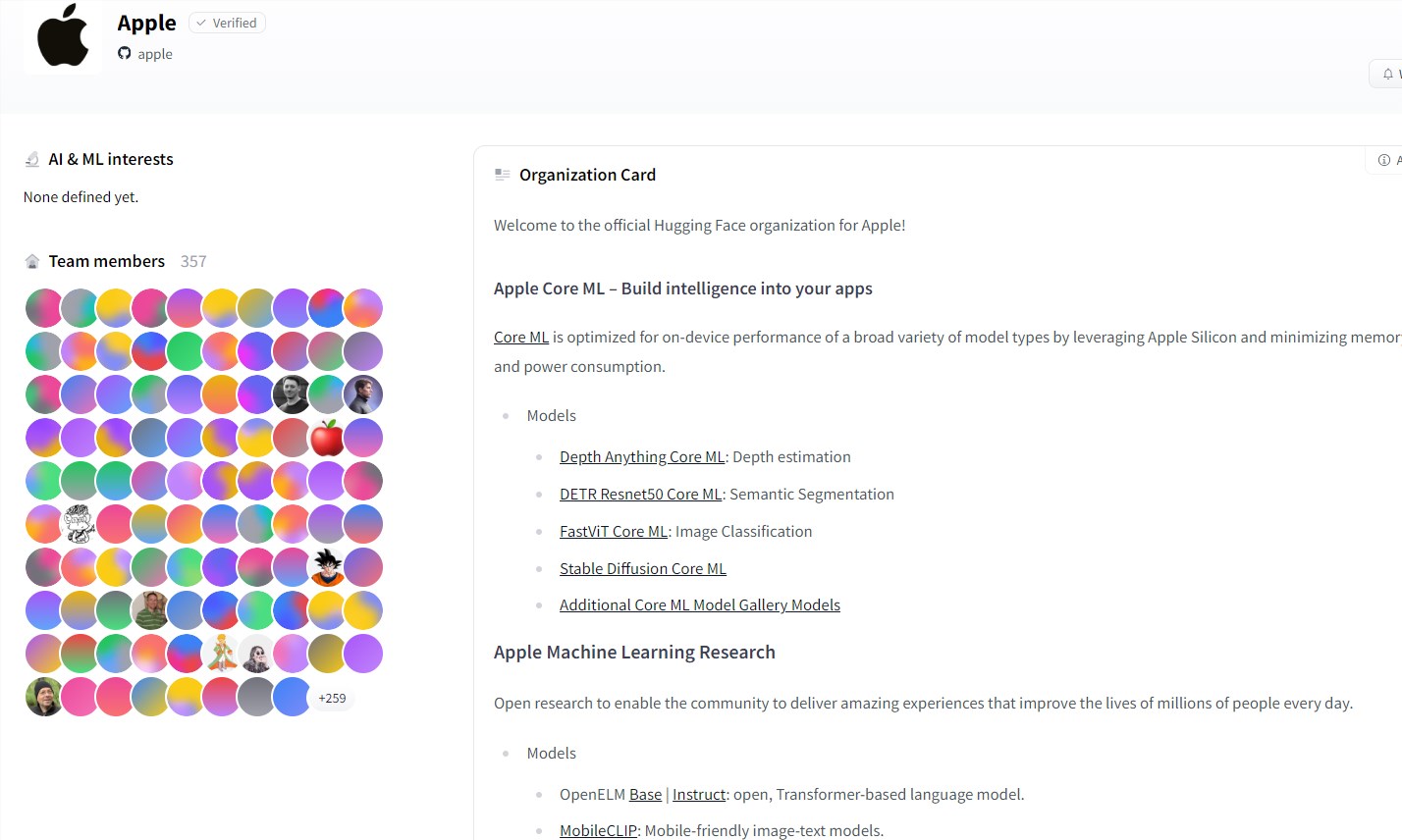
【AiBase提要:】
🚀 苹果在Hugging Face平台发布了20个新的Core ML模型和4个数据集,推动AI发展。
💡 新发布的Core ML模型涵盖了广泛的应用,包括图像分类、单目深度估计和语义分割。
🔒 苹果强调设备AI的重要性,优化的模型在用户设备上运行,提升应用程序性能并保障用户数据安全和隐私。
详情链接:https://huggingface.co/apple
6、ElevenLabs开源视频生成音效工具 上传视频即可自动配音
ElevenLabs是一家专注于音频生成技术的公司,最近宣布涉足视频生成领域,开源了一个项目可以自动为上传的视频配音,生成合适的音效。他们推出了新功能,用户可以通过输入文本生成各种逼真的音乐特效,为电影、游戏、短视频等行业带来巨大帮助。除音效生成外,还提供语音克隆和文本转语音等强大功能。
【AiBase提要:】
🔊 自动为上传视频配音,生成合适音效
🎶 输入文本生成各种逼真音乐特效,帮助电影、游戏、短视频行业
🎤 提供语音克隆和文本转语音功能,赋予内容更生动表现形式
文本转音频入口:https://top.aibase.com/tool/elevenlabs-wenbenzhuanyinxiaoapi
视频自动配音入口:https://top.aibase.com/tool/elevenlabs-texts-to-sounds-effects-api
7、腾讯微信视频号拟限制数字人带货
腾讯视频号近日宣布了对《视频号橱窗达人发布低质量内容实施细则》的修订,旨在加强内容质量监管,并拟禁止数字人直播带货。该修订于今年 6 月 7 日至 6 月 13 日公开征集意见。
【AiBase提要:】
⭐ 修订细则旨在加强视频号内容质量监管
⭐ 禁止数字人直播带货,明确禁止非真实直播内容
⭐ 平台将对违规者采取相应处罚措施
详情:https://www.chinaz.com/2024/0618/1624007.shtml
8、Stability AI的SD3因许可问题遭反对,CivitAI社区封禁相关内容
Stability AI最新发布的重大模型SD3因许可问题引发争议,面临AI社区反对。CivitAI社区封禁与SD3相关内容,引发许可协议争议。公司推出面向消费者的创作者许可,限制开发者条件和图像生成数量。SD3存在无法生成特定人体姿势等问题,未来不确定。CEO离职裁员,公司需解释新许可协议影响。整个争议对AI社区和开源模型发展有潜在影响。
【AiBase提要:】
💥 SD3许可问题引发争议,面临AI社区反对。
🔒 公司推出创作者许可,限制开发者条件和图像生成数量。
❓ SD3存在无法生成特定人体姿势等问题,未来不确定。
9、乐高打印机Pixelbot 3000
这篇文章介绍了YouTube频道创作者@Creative Mindstorms设计制造的Pixelbot3000乐高打印机,利用自定义代码和人工智能生成乐高马赛克。用户只需输入艺术作品名称,AI生成图像后Pixelbot3000自动组装马赛克。

【AiBase提要:】
🤖 利用自定义代码和人工智能,Pixelbot3000能够自动生成乐高马赛克,简化了打印过程。
🎨 Pixelbot3000使用OpenAI的DALL-E3生成卡通风格简化图像,最终产生高对比度的缩放图像。
🔧 Pixelbot3000通过分割AI生成的图像并采样每个方格中心像素的颜色,得到更好的马赛克图案。
10、研究人员教会 AI 识别人类线描的草图
这篇文章介绍了萨里大学和斯坦福大学研究团队开发的新方法,教会人工智能理解人类线描草图的重要性和成果。通过结合草图和文字描述,人工智能展现出接近人类水平的理解能力,对复杂场景中的对象进行准确识别和标记。这一研究为人机交互和设计工作流程带来了新的可能性。

【AiBase提要:】
🧠 人工智能学习理解草图的重要性,展现出接近人类水平的表现
🌳 人工智能能以85%准确度识别和标记风筝、树、长颈鹿等对象,超越其他模型
🎨 新方法不仅适用于非艺术家绘制的草图,还适用于没有明确训练的对象绘制的草图
详情链接:https://arxiv.org/abs/2312.12463
11、研究:AI生成图像未能准确呈现伊斯兰建筑文化细微差异
人工智能(AI)在建筑设计领域带来革命性变革,但在伊斯兰建筑等文化敏感领域,AI生成的图像未能正确呈现历史元素。研究指出AI生成器存在历史知识不足,建议谨慎使用。作者认为AI可成为有价值工具,但需结合人类专业知识和文化敏感度。

【AiBase提要:】
🏗️ AI在建筑设计中革命性变革,但在伊斯兰建筑领域存在挑战。
🕌 AI生成器历史知识不足,未能准确呈现伊斯兰建筑文化细节。
🤖 AI应作为增强人类创造力的工具,结合专业知识和文化敏感度。
(举报)