
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
新鲜AI产品点击了解:https://app.aibase.com/zh
1、可灵AI今日全量上线O1 视频大模型:统一多模态架构 支持一句话生成视频
可灵AI公司宣布其自主研发的O1视频大模型已全量开放,该模型采用MVL统一交互架构,支持文字、图像、视频三种指令输入,并能一次性完成文生视频、图生视频、局部编辑及镜头延展任务。此外,模型通过多视角主体构建技术解决镜头切换时的“特征漂移”问题,确保画面连贯。目前,O1模型已在可灵App及官网同步开放体验,后续将开放API接口供第三方平台集成。

【AiBase提要:】
🧠 O1视频大模型采用MVL统一交互架构,支持文字、图像、视频三种指令输入
🎬 一次性完成文生视频、图生视频、局部编辑及镜头延展任务
📊 可灵AI计划开放API接口,供第三方平台集成
2、千问APP接入万相Wan2.5,视频能力全新升级
千问APP接入万相Wan2.5模型,显著提升了视频创作能力,支持音视频同步输出,并允许用户通过自定义图片和文字生成高质量的动态视频内容,进一步降低了创作门槛,激发了用户的创意热情。

【AiBase提要:】
🎥 千问APP接入万相Wan2.5模型,视频创作能力全面升级。
🎙️ 支持音视频同时输出,实现音画同步的高质量视频生成。
🔄 用户可自定义上传照片和文字,生成动态唱跳视频,降低创作门槛。
3、PixVerse V5.5 发布:支持「导演级」音画同步
PixVerse V5.5版本的发布,为视频制作带来了重大变革。用户只需输入一句话即可生成带声音和口型同步的高清视频,并支持多镜头自动切换,显著提升了视频创作的便捷性。

【AiBase提要:】
🎥 支持一句话生成高清视频,实现音画同步。
🔄 多镜头自动切换,提升视频叙事逻辑。
🚀 自研架构提升视频生成速度与质量,一站式服务。
详情链接:https://pai.video
4、DeepSeek-V3.2 正式发布:引入创新稀疏注意力架构,API 成本腰斩,性能比肩顶尖闭源模型
中国人工智能初创公司深度求索(DeepSeek AI)发布了DeepSeek-V3.2系列模型,包括DeepSeek-V3.2及其高计算增强版DeepSeek-V3.2-Speciale。新模型引入了创新的稀疏注意力机制(DSA),提升了长文本任务的效率,并降低了API成本。DeepSeek-V3.2-Speciale版本在高难度推理任务中表现出色,甚至超越了GPT-5。此外,该模型还提供了开源内核和演示代码,支持研究人员和企业进行商业部署。
【AiBase提要:】
🧠 引入创新的稀疏注意力机制(DSA),提升长文本任务效率。
🚀 DeepSeek-V3.2-Speciale版本在高难度推理任务中表现优异,超越GPT-5。
📊 API成本降低50%,支持研究人员和企业进行商业部署。
详情链接:https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
5、Runway 发布全新 Gen-4.5视频生成模型,提升创作与视觉质量
Runway 发布了其最新的视频生成模型 Gen-4.5,显著提升了视觉准确性和创意控制,适用于社交媒体短视频创作。尽管面临竞争,Gen-4.5在物体和角色的一致性质量上表现突出,但也存在因果推理和时间连贯性的问题。同时,AI生成内容的真实性问题引发行业讨论,建议添加免责声明。
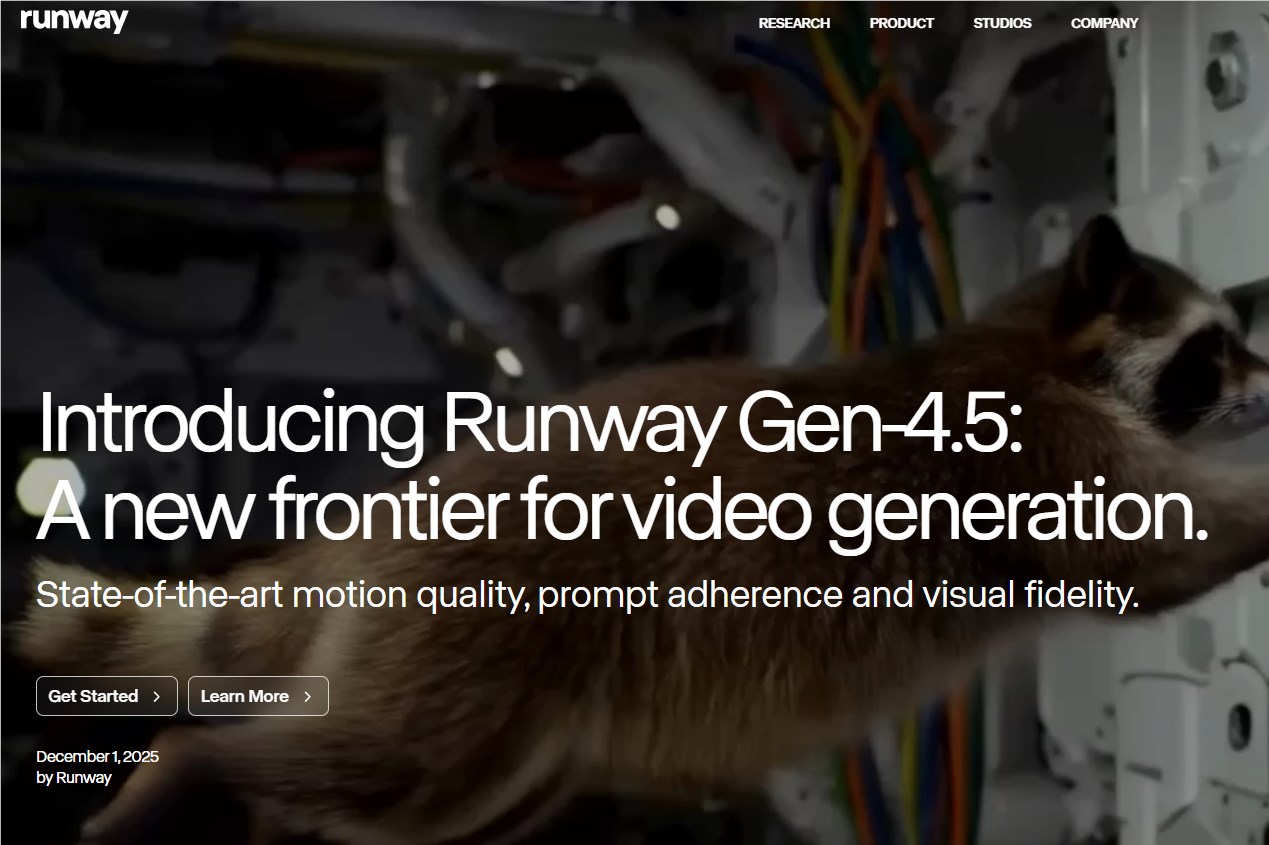
【AiBase提要:】
🎥 Runway 的 Gen-4.5模型使视频生成更具创意和视觉一致性。
📱 该模型主要针对社交媒体短视频,与其他竞争对手针对长视频的战略有所不同。
⚖️ AI 生成内容的真实性问题引发了行业内部的讨论,建议添加免责声明以区分真实与虚假。
6、谷歌 AI 搜索体验“提速”:新设计实现无缝对话,Gemini3Pro 杀入120国市场!
谷歌公司正在采取一系列举措,旨在让其人工智能(AI)模式和功能更加普及和易用。一方面,谷歌正在测试新的设计,以优化用户从 AI 概览到 AI 模式的过渡体验;另一方面,Gemini3Pro 模型正在进行大规模国际扩张。

【AiBase提要:】
💡优化AI体验,实现无缝对话
🌍Gemini3Pro/Nano Banana Pro拓展至120个国家和地区
🚀提升用户在Google搜索中的AI功能
7、Lovart Touch Edit 上线:轻点即改,AI 图像编辑进入“零蒙版”时代
Lovart 推出的 Touch Edit 功能通过自然语言指令和智能识别技术,实现了图像编辑的高效与便捷。用户无需手动操作即可完成复杂的图像修改任务,显著提升了设计效率。

【AiBase提要:】
✨ Touch Edit 核心功能:通过自然语言指令实现图像元素的自动识别与编辑。
🧩 Select & Remix 支持多图混搭,用户可拖拽重组不同图片元素。
⚙️ 技术集成:融合 GPT-4o、Flux Pro 和 Sora 等模型,提供高效的 AI 工作流。
8、蚂蚁数科Agentar入选中国智能体开发赛道“第一梯队”
蚂蚁数科的Agentar平台凭借技术架构的完整性、产品迭代的成熟度以及在金融领域的多年沉淀,成功跻身中国智能体开发赛道的‘第一梯队’,展现了其在AI智能体开发领域的领先地位。
【AiBase提要:】
🧠 蚂蚁数科的Agentar平台在智能体开发领域展现出领先实力。
💼 该平台在金融领域有丰富的技术经验与规模化落地成果。
📈 Agentar-Fin-R1推理大模型在三项金融基准测试中位列第一。
(举报)